Графы, лапласиан, кластера и т.п.
Графы и всевозможные алгоритмы с ними связанные, раньше входили в тройку лидеров по популярности в разнообразных книжках про программирование, наряду с алгоритмами сортировки и поиска. Теория графов область весьма обширная и пытаться объять её во всей полноте возможных задач в одной статье (или даже в нескольких статьях) совершенно бесполезно, народ пишет серьёзные толстые книжки и при этом тоже далеко не о всех возможных аспектах рассказывает.
Однако, есть желание не особо углублясь во всякого рода хроматические числа, гамильтоновы циклы и прочие познавательные вещи, разобраться с некоторыми базовыми наработками в теории графов и отталкиваясь от них перейти к нейронным сетям на этих графах построенных.
Общие определения
Начнем с формального определения. Граф $\mathcal G = (\mathcal V, \mathcal E)$ есть пара множеств: $\mathcal V$ - вершин и $\mathcal E$ - рёбер. Вершины обычно обозначаются $\mathcal V = \{v_i\}$ а рёбра: $\mathcal E=\{e_{ij} = (v_i, v_j)\}$. $e_{ij}$ - ребро, выходящее из вершины с индексом $i$ и приходящее в вершину с индексом $j$.
Графы бывают ориентированные - когда каждое ребро имеет определенное направление, и неориентированные - когда ребро просто связывает две вершины не упорядоченно или, по другому говоря, если в неориентированном графе есть ребро $e_{ij}$, то обязательно присутствует и ребро $e_{ji}$.
Для графа с $\vert \mathcal V \vert = N$ вершинами можно задать матрицу смежности $W \in\mathbb R^{N\times N}$ элемент $w_{ij}$ которой характеризует ребро $e_{ij}$. В простейшем случае, $w_{ij} = 1$ - если ребро $e_{ij}$ есть и $w_{ij} = 0$ - если такого ребра нет. Очевидно, что для неориентированного графа, эта матрица будет симметричной.
Интересная особенность матрицы смежности заключается в том, что в матрице $W^k$ элемент на позиции $(i,j)$ есть число путей длины $k$, которыми можно добраться из вершины $i$ в вершину $j$.
В более общем случае каждому ребру $e_{ij}$ можно приписать некоторый вес $w_{ij}$ и таким образом получить взвешенный граф.
В дальнейшем мы будем работать с взвешенными неориентированными графами. Если эта пара свойств графа не будет нужна или будет вредна, то это будет оговорено отдельно.
Как в задаче появляются графы?
На самом деле в большинстве случаев граф в задаче появляется вполне естественным образом, например, когда рссматривается дорожная или электрическая сеть, эта сеть уже есть граф. Но иногда граф не задан в явном виде, например, пусть у нас есть набор $x_1, …, x_N$ точек, и для каждой пары точек $x_i, x_j$ задана либо метрика схожести $s_{ij}$ либо расстояние $d_{ij}$ между точками.
Очевидно, что при построении графа на таких данных в качестве множества вершин берется множество точек $\{x_i\}_{i=1}^N$. Рёбра же можно выбрать несколькими способами, главное, чтобы граф моделировал свойство локальной связи между точками (в [2] описаны три разных способа):
-
Полный граф. На самом деле самый очевидный способ, это создать полный граф (т.е. у которого есть ребро для каждой пары вершин), задав в качестве веса ребра $w_{ij}$ значение метрики схожести $s_{ij}$.
-
Граф по $\epsilon$-окрестности. В данном случае соединим ребрами только те вершины расстояние между которыми меньше некоторого наперед заданного $\epsilon$. Поскольку $\epsilon$ выбирается обычно достаточно малым, то связанные вершины грубо можно считать примерно одинаково близкими поэтому добавление веса на ребро в такой ситуации не добавляет информации, и граф по $\epsilon$-окрестности обычно строится невзвешенным.
-
Граф по $k$-ближайшим соседям. Здесь мы добавляем ребро $e_{ij}$, если вершина $v_j$ находится в числе $k$ ближайших соседей к вершине $v_i$. Проблема в том, что при таком подходе мы легко можем получить ориентированный граф, потому что возможна ситуация, когда $v_j$ находится в числе $k$ ближайших к вершине $v_i$, но не наоборот (т.е. $v_i$ не находится в числе $k$ ближайших к вершине $v_j$). Чтобы убрать ориентированность графа есть два варианта.
Первый - просто не учитывать ориентацию ребра, т.е. если $v_j$ находится в числе $k$ ближайших к вершине $v_i$, то в граф мы добавляем и ребро $e_{ij}$ и ребро $e_{ji}$. Получившийся граф обычно и называют граф по $k$-ближайшим соседям.
Другой вариант, это добавлять пару рёбер $e_{ij}$ и $e_{ji}$ только если выполены оба условия и $v_j$ находится в числе $k$ ближайших соседей к вершине $v_i$ и $v_i$ в свою очередь находится в числе $k$ ближайших к вершине $v_j$. Полученный таким образом граф называют граф по $k$-ближайшим взаимным соседям.
Лапласиан графа
Введём понятие степень вершины $v_i \in \mathcal V$:
\[d_i = \sum_{j=1}^N w_{ij}\]Для невзвешенного графа это будет просто количество рёбер выходящих из вершины $v_i$, для взвешеного сумма весов таких рёбер. Составим из $d_i$ матрицу степеней (degree matrix):
\[D = \begin{pmatrix} d_{1} & & 0\\ & \ddots & \\ 0 & & d_{N} \end{pmatrix}\]Теперь для графа определим понятие Лапласиана, обычно в литературе встречается три варианта:
- Ненормализованный Лапласиан.
- Нормализованный симметричный Лапласиан.
- Нормализованный несимметричный Лапласиан.
Замечания.
-
В первом и втором случаях матрицы очевидно будут симметричными в силу симметричности $W$ и $D$.
-
Нормализованный симметричный Лапласиан (см., например, [6]) полезен тем, что все его собственные числа не превышают $2$, причем максимум достигается только в случае когда граф двудольный.
-
Последний вариант Лапласиана тесно связан с матрицей переходов $P = D^{-1} W$ при случайном блуждании (random walk). Случайное блуждание - это алгоритм (применяется для кластеризации, например), когда мы встаём в некоторую начальную вершину и перемещаемся из нее случайным образом, выбирая для перехода ребро пропорционально его весу.
В дальнейшем мы будем пользоваться либо первым либо вторым определением.
Не трудно показать, что для любого вектора $f = (f_1, f_2, …, f_N) \in \mathbb R^N$ выполняются равенства:
\[\begin{align*} f^T \mathcal L f &= \frac 1 2 \sum_{i,j=1}^N w_{ij}(f_i - f_j)^2\\ f^T \mathcal L_{sym} f &= \frac 1 2 \sum_{i,j=1}^N w_{ij}\left(\frac {f_i} {\sqrt {d_i}} - \frac {f_j} {\sqrt {d_j}}\right)^2 \end{align*}\]А значит и $\mathcal L$ и $\mathcal L_{sym}$ неотрицательно определенные симметричные матрицы.
Для лапасиана (мы пока остановимся на двух симметричных вариантах, хотя для $\mathcal L_{rw}$ имеют место примерно теже свойства со скидкой на отсутствие симметрии) можно найти собственные числа и собственные вектора. В силу того, что матрицы симметричны, и неотрицательно определены, у нас будет $\lambda_1 \le \lambda_2 \le … \le \lambda_N$ вещественных собственных чисел. При этом и у $\mathcal L$ и у $\mathcal L_{sym}$ наименьшим собственным числом будет $\lambda = 0$ кратность которого совпадает с числом компонент связности графа (доказательство можно найти, например, в [1]) и собственное подпространство соответствующее $\lambda = 0$ есть линейная оболочка векторов вида:
\[\left(\chi_{A_i}(v_1), \chi_{A_i}(v_2), ..., \chi_{A_i}(v_N)\right), \, i=1,...,k,\]где $\chi_{A_i}$ - характеристическая функция компоненты связности $A_i$ (т.е. равна единице на вершинах из данной компоненты связности и нулю на остальных).
Базируясь на этом свойстве лапласиана, строятся алгоритмы кластеризации графа. Мы не будем углубляться в эту весьма познавательную тему, она достаточно подробно раскрывается, например, в [1].
Рассмотрим только один пример для понимания на чем основан подход к кластеризации с использованием лапласиана.
Возьмём граф вида:

Видно, что он состоит из двух компонент связности. На следующих графиках по вертикальной оси изображены координаты собственных векторов лапласиана (собственные вектора и их графики упорядочены по возрастанию, соответствующих собственных значений):
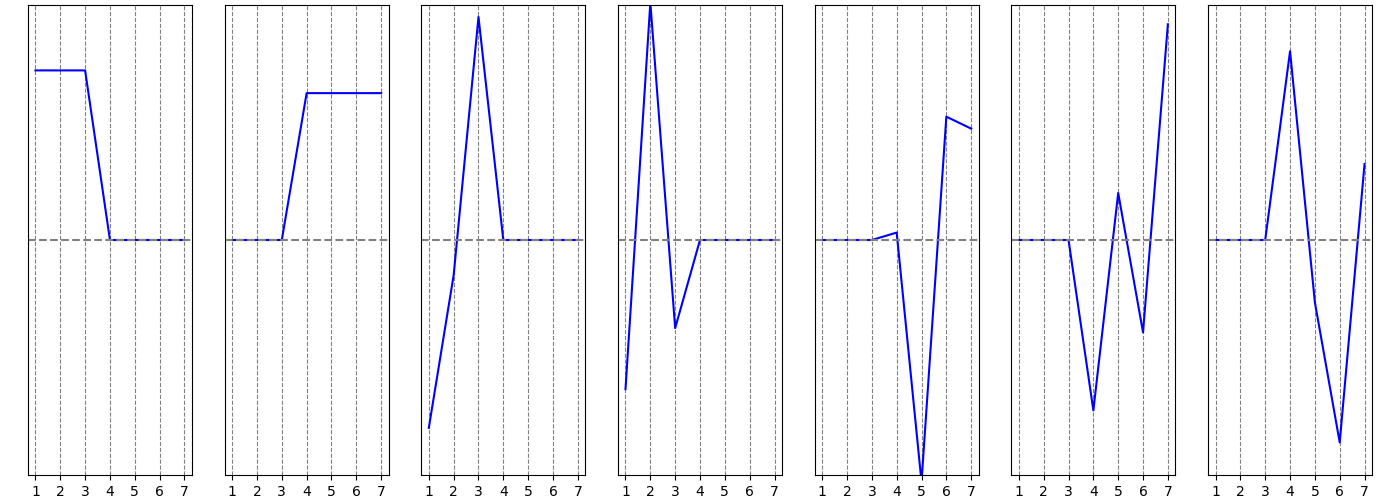
Первые два графика это собственные вектора, соответствующие собственному числу $\lambda = 0$. Видно, что у первого собственного вектора ненулевые координаты соответствуют вершинам $1, 2, 3$, а у второго - $4, 5, 6, 7$. В принципе, этого достаточно для понимания того, что лежит в основе подхода к кластеризации на базе лапласиана. Но если присмотреться к следующим графикам, то на них видно, что второй и третий “разделяют” вершины внутри первого кластера, остальные “разделяют” вершины второго.
Теперь соединим две компоненты связности ребром:

и построем такие же графики координат собственных векторов:
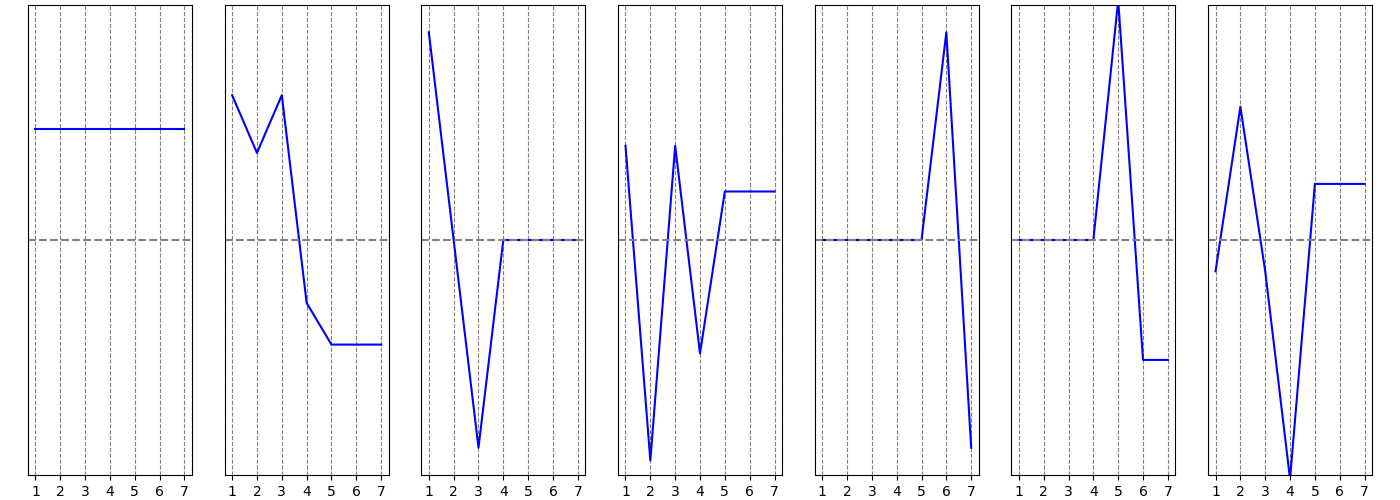
Все координаты первого вектора равны между собой, он соответствует собственному числу $\lambda = 0$ (степень этого собственного числа равна 1, что совпадает с числом компонент связности графа $\mathcal G_2$). Второй вектор “разделяет” вершины, положительные координаты этого вектора соответствуют вершинам $1, 2, 3$, а отрицательные вершинам $4, 5, 6, 7$. Если продолжать анализ этого вектора, то можно отметить, что абсолютные значения координат для вершин $1$ и $3$ одинаковые и больше абсолютного значения координаты для вершины $2$, аналогично вершина $4$ выделяется относительно вершин $5, 6, 7$, связано это с тем, что именно между вершинами $2$ и $4$ мы добавили ребро, соединяющие две отдельные компоненты, которые были в графе $\mathcal G_1$.
Следует отметить еще один факт, который будет нам полезен в дальнейшем. Мы уже отмечали, что если взять $s$-ую степень матрицы смежности (невзвешенной), то элемент $\left(W^s\right)_{ij}$ есть число путей длины $s$, которыми можно добраться из вершины $i$ в вершину $j$. Более слабое утверждение, что
Если из вершины $i$ в вершину $j$ нельзя добраться быстрее чем за $s + 1$ шаг, то $\left(W^s\right)_{ij} = 0$
Оказывается такое же утверждение можно доказать и для лапласиана графа (см. [4], параграф 5):
Пусть $\mathcal G$ - взвешенный граф, $\mathcal L$ - его лапласиан (нормализованный или нет) и $s>0$ - целое число, то для любых двух вершин $i$ и $j$, минимальная длина пути между которыми $d_{\mathcal G}(i, j) > s$ имеем $ \left( \mathcal L^s\right)_{ij} = 0 $
Сигналы на графе, их гладкость и лапласиан
Допустим теперь, что каждой вершине $v_i$ графа приписана некоторая величина $f_i$:
\[f: \mathcal V \rightarrow \mathbb R\]или, что тоже самое задан вектор $f = (f_1, f_2, …, f_N) \in \mathbb R^N$ $i$-ая координата которого определяет значение функции $f$ в $i$-ой вершине графа.
Чтобы показать связь оператора Лапласа на пространстве функций с лапласианом графа, рассмотрим, вначале, дискретный сигнал $\{f_{m\,n} \vert m = 1,…,M;\, n = 1,…,N\}$ на равномерной двумерной решетке с шагом $d$:

В этом случае лапласиан сигнала можно определить представив частные производные в виде разностей (и перейти таким образом для начала от непрерывного случая к дискретному):
\[(\Delta f)_{m\,n} = \frac {f_{m+1\,n} + f_{m-1\,n} + f_{m\,n+1} + f_{m\,n - 1} - 4 f_{m\,n}} {d^2}\]Если теперь естественным образом заменить решетку на граф:

положив вес рёбер равным $\frac 1 {d^2}$ получим весовую матрицу:
\[W = \begin{pmatrix} 0 & \frac 1 {d^2} & \frac 1 {d^2} & \frac 1 {d^2} & \frac 1 {d^2}\\ \frac 1 {d^2} & 0 & 0 & 0 & 0\\ \frac 1 {d^2} & 0 & 0 & 0 & 0\\ \frac 1 {d^2} & 0 & 0 & 0 & 0\\ \frac 1 {d^2} & 0 & 0 & 0 & 0\\ \end{pmatrix}\]отсюда
\[\mathcal L = \begin{pmatrix} \frac 4 {d^2} & -\frac 1 {d^2} & -\frac 1 {d^2} & -\frac 1 {d^2} & -\frac 1 {d^2}\\ -\frac 1 {d^2} & \frac 1 {d^2} & 0 & 0 & 0\\ -\frac 1 {d^2} & 0 & \frac 1 {d^2} & 0 & 0\\ -\frac 1 {d^2} & 0 & 0 & \frac 1 {d^2} & 0\\ -\frac 1 {d^2} & 0 & 0 & 0 & \frac 1 {d^2}\\ \end{pmatrix}\]и, наконец,
\[\left[\mathcal L \cdot \begin{pmatrix} f_{m\,n}\\ f_{m\,n+1}\\ f_{m-1\,n}\\ f_{m\,n-1}\\ f_{m+1\,n} \end{pmatrix} \right]_{mn} = \frac {4 f_{m\,n} - f_{m+1\,n} - f_{m-1\,n} - f_{m\,n+1} - f_{m\,n - 1}} {d^2} = -(\Delta f)_{m\,n}\]Т.е. в случае равномерной решётки, воздействие лапласиана $\mathcal L$ графа, соответствующего этой решётке, на сигнал $f$ в вершинах графа равен лапласиану (с обратным знаком правда) функции $f$.
Для сигнала $f$, заданного на графе $\mathcal G = (\mathcal V, \mathcal E)$ определим производную сигнала $f$ по ребру $e_{ij}$ в вершине $v_{i}$:
\[\left. \frac{\partial f}{\partial e_{ij}} \right\vert_{v_i} = \sqrt {w_{ij}} (f_j - f_i)\]учтя это, можно определить градиент сигнала $f$ в вершине $v_{i}$:
\[\nabla_{v_i} f = \left\{ \left.\left. \frac{\partial f}{\partial e_{ij}} \right\vert_{v_i} \right\vert w_{ij} \neq 0 \right\}\]локальную вариацию в вершине $v_{i}$ можно записать как норму градиента в этой вершине:
\[\left \| \nabla_{v_i} f \right \|_2 = \left(\sum_{j=1}^N \left(\left. \frac{\partial f}{\partial e_{ij}} \right\vert_{v_i}\right)^2\right)^{\frac 1 2} = \left(\sum_{j=1}^N w_{ij} (f_j - f_i)^2\right)^{\frac 1 2}\]Эту норму можно рассматривать как характеристику локальной гладкости сигнала $f$ в вершине $v_i$ (суммирование идёт по всем $j$, т.е. по всем вершинам графа, но за счёт весов, в суммирование учавствуют только “соседние” к $v_i$ вершины), эта величина мала, если значение функционала в $i$-ой вершине мало отличается от значений функционала в соседних вершинах (связанных рёбрами с $v_i$).
Если теперь рассмотреть вектор
\[\nabla_{\mathcal G} f = \left(\left \| \nabla_{v_1} f \right \|_2, \left \| \nabla_{v_2} f \right \|_2, ..., \left \| \nabla_{v_N} f \right \|_2 \right)\]то его норма будет глобальной вариацией сигнала на графе:
\[\left \| \nabla_{\mathcal G} f \right \|_2 = \left(\sum_{i,j=1}^N w_{ij} (f_j - f_i)^2\right)^{\frac 1 2} = \left( 2 f^T \mathcal L f \right)^{\frac 1 2}\]Т.о. лапласиана вбирает в себя структурные свойства графа, и в некотором смысле может показать “согласованность” сигнала со структурой графа.
Рассмотрим в качестве примера один и тот же сигнал $f = (0, 1, 2, 2, 2, -1, -2, -2, -2)$, на трёх разных графах отличающихся только конфигурацией рёбер (пример взят из [2], во всяком случае идейно):

Очевидно, что сигнал наиболее согласован со структурой графа $\mathcal G_1$, на втором эта согласованность уменьшается за счёт появления рёбер между вершинами в которых значение сигнала сильно отличается, на третьем графе эта рассогласованность ещё больше усиливается.
А теперь сравним величину $f^T \mathcal L f$ на всех трёх графах:
-
$f^T \mathcal L_{\mathcal G_1} f = 4$
-
$f^T \mathcal L_{\mathcal G_2} f = 36$
-
$f^T \mathcal L_{\mathcal G_3} f = 51$
Действительно, наша интуитивная оценка согласованности сигнала со структурой графа, подтвердилась.
Преобразование Фурье
В функциональном анализе с лапласианом, тесно связано понятие преобразования Фурье.
У графа мы тоже научились находить лапласиан и даже показали схожесть лапласиана на графе и лапласиана на пространстве функций. Теперь, воспользуемся лапласианом, чтобы определить преобразование Фурье.
Для лапласиана $\mathcal L$ мы можем найти собственные числа $0=\lambda_1 \le \lambda_2 \le … \le \lambda_N$ и собственные вектора:
\[\left\{u^{(k)} = \left(u^{(k)}_1, u^{(k)}_2,..., u^{(k)}_N\right) \right\}_{k=1}^N\]Собственные вектора выберем таким образом, чтобы они составляли ортонормированный базис пространства $\mathbb R^N$. Если из этих векторов составить матрицу $U = (u^{(1)}, u^{(2)},…, u^{(N)})$ (вектора - столбцы матрицы), то эта матрица будет ортогональной, т.е. $U U^T = U^T U = I$.
А еще можно записать разложение: $\mathcal L=U \Lambda U^T$, где $\Lambda = \mathrm{diag}(\lambda)$ - диагональная матрица, составленная из собственных чисел лапласиана.
Теперь определим преобразование Фурье на графе сигнала $f = (f_1, f_2, …, f_N)^T \in \mathbb R^N$ как сигнал:
\[\tilde f = U^T f = (\tilde f_1, \tilde f_2, ..., \tilde f_N)^T\]не трудно видеть, что $i$-ая координата преобразования Фурье определяется формулой (скалярное произведение векторов $u^{(i)}$ и $f$):
\[\tilde f_i = \sum_{j=1}^N u^{(i)}_j f_j,\, i = 1, ..., N\]Поскольку $U$ ортогональная матрица, то очевидно имеет место и обратное преобразование:
\[U \tilde f = U \cdot \left(U^T f\right) = I f = f\]С преобразованием Фурье тесно связаны понятия спектра и частот. В данном случае в качестве частот у нас выступают собственные числа лапласиана графа. Определив преобразование Фурье на графе, мы можем применять к сигналам заданным на этом графе фильтры не только непосредственно (например, заменяя сигнал в вершине графа на взвешенное среднее по сигналу в соседних к данной вершинах), но и в частотной области, например, удаляя из сигнала высокие частоты (т.е. зануляя коэффициенты Фурье $\tilde f_i$, соответствующие большим $\lambda_i$).
Здесь надо заметить, что для картинок (сигнала на двумерной решётке), процесс “удаления из сигнала высоких частот” тесно связан с очисткой от зашумленности.
Произвольный фильтр в частотной области можно определить как вектор: $\tilde\theta = \left(\tilde\theta_1, \tilde\theta_2,…, \tilde\theta_N\right)$, его применение будет выглядеть как поэлементное произведение вектора $\tilde \theta$ на вектор $\tilde f$:
\[\tilde g = \tilde \theta \odot \tilde f\]или, если сделать из вектора $\tilde \theta$ диагональную матрицу, то поэлементное умножение, заменится умножением матрицы на вектор:
\[\tilde g = \mathrm{diag}(\tilde \theta) \tilde f\]Используем обратное преобразование Фурье и тогда полное применение фильтра $\tilde \theta$ на графе $\mathcal G$ к сигналу $f$ можно записать в виде:
\[g = U \cdot \mathrm{diag}(\tilde \theta) \cdot U^T f\]Вернемся к примеру сигнала $f = (0, 1, 2, 2, 2, -1, -2, -2, -2)$ на трёх разных графах:
посчитаем преобразование Фурье, и отложим по горизонтальной оси частоты (собственные числа лапласиана), а по вертикальной значение коэффициентов Фурье для соответствующих частот:
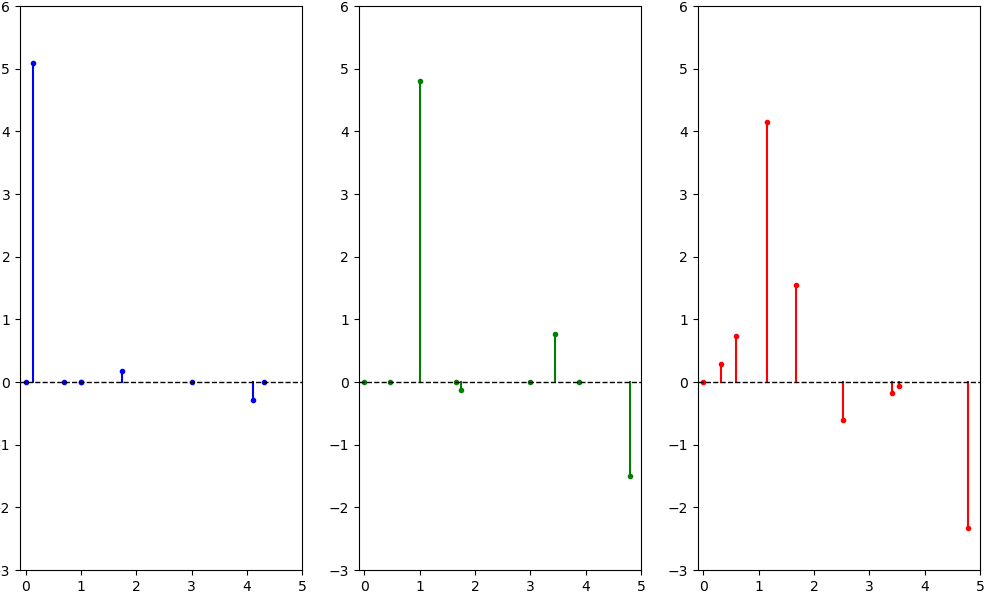
Теперь оставим только низкие частоты, используя в качестве $\tilde \theta = \left(1, 1, 1, 0, 0, 0, 0, 0, 0\right)$ (занулим у преобразования Фурье сигналов, все координаты кроме первых трёх). Отфильтровав таким образом высокие частоты, и сделав обратное преобразование Фурье получим новые сигналы на графах:

На изображении значение сигналов округлено до десятых.
Если двигаться по рёбрам, видно, что отбрасывание высоких частот действительно в некотором смысле “сгладило” сигнал.
Свёртка сигналов на графе
Мы можем рассмотреть $\tilde \theta$ из предыдущего пункта, как преобразование Фурье некоторого сигнала $\theta$ на графе, и восстановить этот сигнал очевидным образом:
\[\theta = U \tilde \theta\]А теперь вспомним одну из основных теорем связанных с преобразованием Фурье - теорему о свёртке.
По аналогии с “теоремой о свёртке”, преобразование $\ast_{\mathcal G}$, задаваемое формулой:
\[f \ast_{\mathcal G} \theta = U \cdot \left((U^T \theta) \odot (U^T f) \right)\]мы будем называть свёрткой сигналов $\theta$ и $f$ на графе $\mathcal G$.
Однако, для практических целей нам интересны свёртки с такими сигналами, аналогами которых в пространстве функций будут финитные функции или, что тоже самое, функции с ограниченным носителем. Т.е. нам желательно, чтобы результат свёртки для вершины формировался на основе сигнала в соседних вершинах. А для этого предлагается представить преобразование Фурье фильтрующего сигнала в виде:
\[\tilde \theta = \left(h(\lambda_1), h(\lambda_2), ..., h(\lambda_N)\right)\]здесь
\[h(\lambda) = \sum_{k=0}^K a_k \lambda^k\]многочлен степени $K$, и для получения координаты $\tilde \theta_i$ мы считаем значение этого многочлена от собственного числа $\lambda_i$. В этом случае:
\[\begin{align*} g &= U \cdot \begin{pmatrix} h(\lambda_1) & & 0\\ & \ddots & \\ 0 & & h(\lambda_N) \end{pmatrix} \cdot U^T f =\\ \\ &= U \cdot \left[ a_0 \cdot I + a_1 \cdot \begin{pmatrix} \lambda_1 & & 0\\ & \ddots & \\ 0 & & \lambda_N \end{pmatrix} + ... +a_K \cdot \begin{pmatrix} \lambda_1^K & & 0\\ & \ddots & \\ 0 & & \lambda_N^K \end{pmatrix} \right]\cdot U^T f =\\ \\ &= U \cdot \left[ a_0\cdot I + a_1 \cdot \Lambda +...+a_K \cdot \Lambda^K\right]\cdot U^T f =\\ \\ &= \left(a_0 \cdot U \cdot I \cdot U^T + a_1 \cdot U \cdot \Lambda \cdot U^T +...+a_K \cdot U \cdot \Lambda^K \cdot U^T\right) f \end{align*}\]так как $U^T U = I$ и $U \Lambda U^T = \mathcal L$, заменим
\[U \Lambda^k U^T = U \Lambda U^T U \Lambda ... U^T U \Lambda U^T = \mathcal L^k\]тогда:
\[\begin{align*} g &= \left(a_0 \cdot I + a_1 \cdot \mathcal L + ... + a_K \cdot \mathcal L^K \right) f \\ &= a_0 \cdot f + a_1 \cdot \mathcal L \cdot f + ... + a_K \cdot \mathcal L^K \cdot f \end{align*}\]а значит, обозначая $\left(\mathcal L^k\right)_{ij}$ элемент матрицы $\mathcal L^k$, стоящий на позиции $i,j$, и полагая, по определению $\mathcal L^0 = I$, можно для того, чтобы получить координаты сигнала $g$, использовать формулу:
\[\begin{align*} g_i &= a_0 f_i + a_1 \sum_{j=1}^N (\mathcal L)_{ij} f_j + ... + a_K \sum_{j=1}^N \left(\mathcal L^K\right)_{ij} f_j = \\ &= \sum_{k=0}^K a_k \sum_{j=1}^N f_j \left(\mathcal L^k\right)_{ij} = \sum_{j=1}^N f_j \sum_{k=0}^K a_k \left(\mathcal L^k\right)_{ij} \end{align*}\]А теперь вспомним свойство степеней лапласиана, а именно $\left(\mathcal L^k\right)_{ij} = 0$, в случае если кратчайший путь между вершинами $i$ и $j$ содержит больше $k$ рёбер. Таким образом, если мы определяем наш свёрточный фильтр в частотной области при помощи многочлена степени $K$ (от собственных чисел лапласиана), то после фильтрации мы получим новый сигнал, который в данной вершине будет линейной комбинацией от сигнала в вершинах отстающих от данной не более чем на $K$ шагов. В каком то смысле мы таким образом получаем свёртку исходного сигнала с сигналом с компактным носителем.
Литература
-
Ulrike von Luxburg. “A Tutorial on Spectral Clustering”, arXiv:0711.0189, 2007
-
D. I. Shuman, S. K. Narang, P. frossard, A. Ortega, P. Vandergheynst, “The Emerging field of Signal Processing on Graphs: Extending High-Dimensional Data Analysis to Networks and Other Irregular Domains”, arXiv:1211.0053, 2013
-
Тиман А. Ф., Трофимов В. Н. “Введение в теорию гармонических функций”, М., 1968 г.
-
D. K. Hammond, P. Vandergheynstb, R. Gribonval, “Wavelets on Graphs via Spectral Graph Theory”, arXiv:0912.3848, 2009
-
Колмогоров А. Н., Фомин С. В. “Элементы теории функций и функционального анализа”, М., 1976 г.
-
F. K. Chung, “Spectral Graph Theory”, 1997