Детектирование объектов под дождем для автомобильных автопилотов.
Авторы разбираются с детектированием объектов в различных погодных условиях, а точнее они хотят определить насколько сильно падает качество детектирования, когда на улице дождь (туман и снег их тоже интересует, но меньше). Они концентрировались на использовании детектора в автомобильном автопилоте, поэтому разбирались с детектированием четырех типов объектов: машины, пешеходы, знаки дорожного движения, светофоры.
Рассматривались две сетки: Faster-RCNN и YOLO, поскольку эти сетки реализуют два несколько разных подхода к детектированию объектов.
В качестве датасета используется BD100K, т.к. у него есть разметка о погодных условиях. Из этого датасета, авторы набрали себе train clear и test clear - фотографии в ясную погоду. И еще один набор test rainy - фотографии под дождем. Пишут, что можно было бы сделать test synthetic rain набор непосредственно из test clear применив какой-то из алгоритмов добавления дождя на фотографию, но они алгоритма который бы делал достаточно хорошо не знают, поэтому от такого отказались. Хотя в этом случае сравнение было бы, в каком-то смысле, более честным. Так же авторы жалуются, что метки погодных условий в BD100K не всегда адекватны, т.е. дождливой погодой может быть отмечены и простая облачность и даже вполне себе солнечный день, поэтому чтобы собрать test rainу набор им пришлось перепроверять всё в ручную. В результате у них получились следующие три набора:
Набор | Автомобили | Пешеходы | Дорожные знаки | Светофоры |
==================================================================
Train clear | 149'548 | 16'777 | 43'866 | 26'002 |
Test clear | 13'721 | 2'397 | 3'548 | 4'239 |
Test rainy | 13'724 | 2'347 | 3'551 | 4'246 |
После сбора датасетов авторы натренировали две сетки: Faster-RCNN и YOLO, используя train clear набор и проверили результат на test clear и test rainy (использовали метрику mAP). Очевидно, что на test rainy качество детекции существенно просело. Причем, детектирование автомобилий и дорожных знаков деградировало меньше, чем детектирование пешеходов и светофоров.
Faster R-CNN
Вариант | V-AP | P-AP | TL-AP | TS-AP | mAP |
===========================================================
test clear | 72.61 | 40.99 | 26.07 | 38.12 | 44.45 |
===========================================================
test rainy | 67.84 | 32.58 | 20.52 | 35.04 | 39.00 |
===========================================================
DDN | 67.00 | 28.55 | 20.02 | 35.55 | 37.78 |
DeRaindrop | 64.37 | 29.27 | 18.32 | 33.33 | 36.32 |
PReNet | 63.69 | 24.39 | 17.40 | 31.68 | 34.29 |
UNIT | 68.47 | 32.76 | 18.85 | 36.20 | 39.07 |
Domain adaptation | 67.36 | 34.89 | 19.24 | 35.49 | 39.24 |
YOLO-V3
Вариант | V-AP | P-AP | TL-AP | TS-AP | mAP |
===========================================================
test clear | 76.57 | 37.12 | 46.22 | 50.56 | 52.62|
===========================================================
test rainy | 74.15 | 32.07 | 41.07 | 50.27 | 49.39|
===========================================================
DDN | 73.07 | 29.89 | 40.05 | 48.74 | 47.94|
DeRaindrop | 70.77 | 30.16 | 37.70 | 48.03 | 46.66|
PReNet | 70.83 | 27.36 | 35.49 | 43.78 | 44.36|
UNIT | 74.14 | 34.19 | 41.18 | 48.41 | 49.48|
Ухудшение качества было ожидаемо, поэтому авторы перешли ко второй часте своей работы и попытались предложить способ борьбы с этим ухудшением.
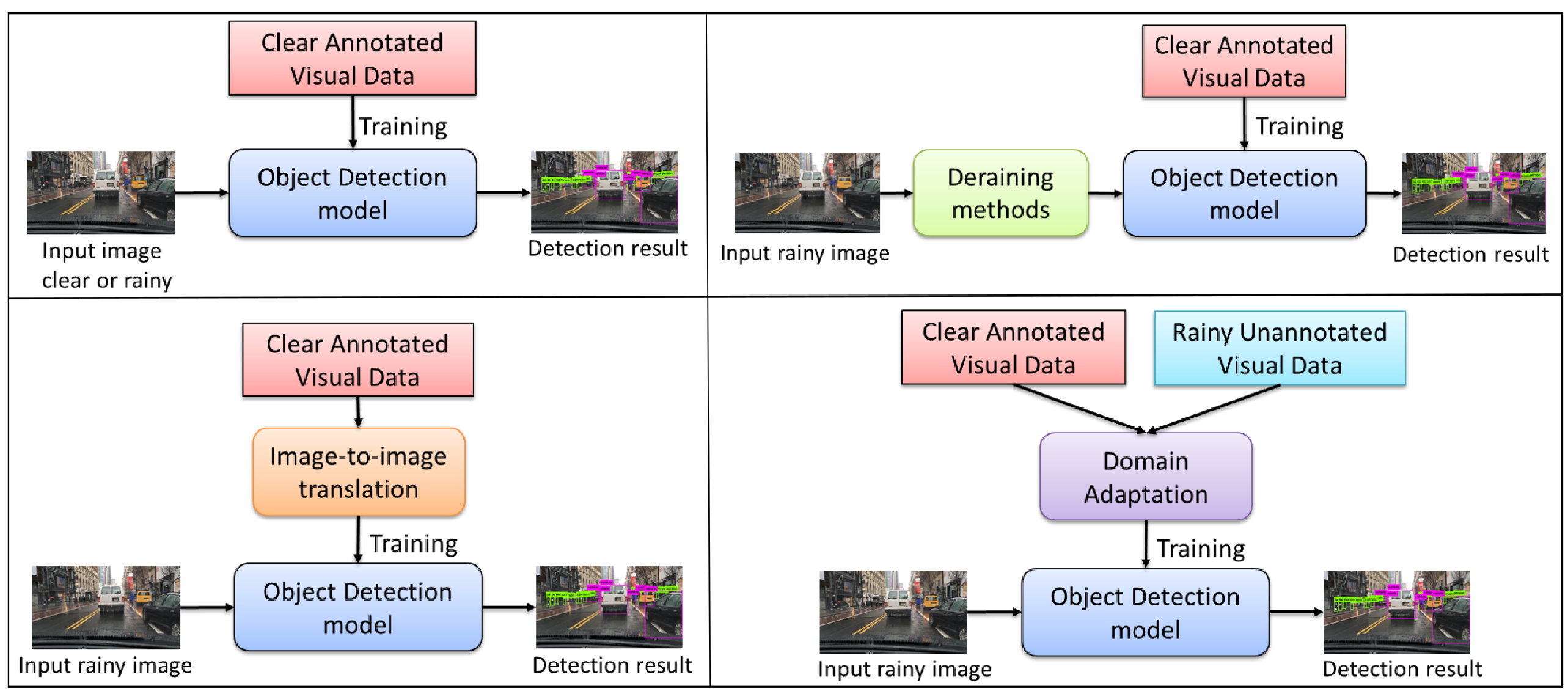
Убираем дождь на тестовом наборе
Авторы попробовали три варианта:
-
Deep Detail Network (DDN). X. Fu et al. “Removing rain from single images via a deep detail network” Здесь тренируется CNN типа ResNet для получения по фотографии - разности, на которую надо эту фотографию изменить, чтобы убрать дождь.
-
DeRaindrop. R. Qian at al. “Attentive generative adversarial network for raindrop removal from a single image” Крайне мудрёная схема включающая в себя Attentive-Recurrent Network (ARN) внутри которой Long Short Term Memory (LSTM) и свёрточные слои, а также Contextual Autoencoder
-
Progressive Recurrent Network (PReNet). D. Ren et al. “Progressive image deraining networks: a better and simpler baseline” Здесь тоже присутствуют свёрточные слои и LSTM, и дождь удаляется с картинки постепенно, т.е. мы засовываем картинку в сеть, потом полученный результат снова в сеть и так до полного удовлетворения.
Результат применения этих алгоритмов можно посмотреть в таблицах. Очевидно, что качество детекции только ухудшается и для Faster-RCNN и для YOLO. Объясняется это тем, что все методы удаления дождя в результате слегка замыливают картинку, сглаживают ребра и за счет этого теряются важные features.
Добавляем дождь на тренировочном наборе
Здесь два варианта:
-
UNsupervised Image-to-image Translation (UNIT). M.-Y. Liu et al. “Unsupervised image-to-image translation networks” Это GAN + VAE, для тренировки не обязательно иметь пары одинаковых фотографий одну в солнечную и дождливую погоду (поэтому unsupervised). Используя такой подход, авторы превратили train clear в train gen rainy и перетренировали на нем Faster RCNN и YOLO. Результаты можно опять посмотреть в таблице, в среднем небольшой прирост есть, в основом за счет улучшения детекции пешеходов. Так что применять такой способ можно, но без особого оптимизма.
-
Domain adaptation. Y. Chen et al. “Domain adaptive faster r-cnn for object detection in the wild” Авторы нашли domain adaptation только для Faster RCNN, поэтому только на ней этот подход и тестируется. Результаты в таблице. Cредний прирост даже выше чем для UNIT.
Выводы
Для себя сделал вывод, что лучший вариант - собрать тренировочный датасет в дождливую погоду, и тренироваться на нем (либо подмешивая его). Если этого не получилось, попытаться еще как-то воздействовать на ситуацию на этапе тренировки (фактически это же аугментация данных просто специфичная), все варианты вычищать картинку на этапе использования - бесперспективны.