Серия фотографий для улучшения очень темных изображений

На самом деле проблема со съёмкой в темноте комплексная, с одной стороны самое очевидное это низкий уровень полезного сигнала, но из этого с необходимостью вытекает не особо высокое соотношение сигнал шум, а значит просто увеличение аплитуды хоть и поможет, но смотреть на фотографию таким образом осветленную можно будет только по необходимости. Можно бороться с темнотой на этапе съёмки - использовать выдержку побольше, или прикрутить к камере вспышку. Но первое возможно, только если снимаем статическую картинку и желательно со штатива. А второе поможет только для достаточно близких к камере объектов. Резюмируя, есть насущная необходимость осветлять темные фотографии и aвторы статьи рассказывают как это делают они.
Как и ананосировано в заголовке для того, чтобы получить одну хорошую светлую фотографию, авторы предлагают снять серию темных снимков, и каким-то образом (известное дело при помощи свёрточных сетей, сейчас без них никуда) восстановить одну светлую красивую картинку. Однако, прежде чем перейти к серии снимков, естественно попытаться начать с одного. Итак первый этап предполагает один темный снимок на входе и один на выходе. Авторы предлагают схему состоящую из двух свёрточных сетей Coarse и Fine, обе эти сети имеют схожую encoder-decoder архитектуру типа U-Net.
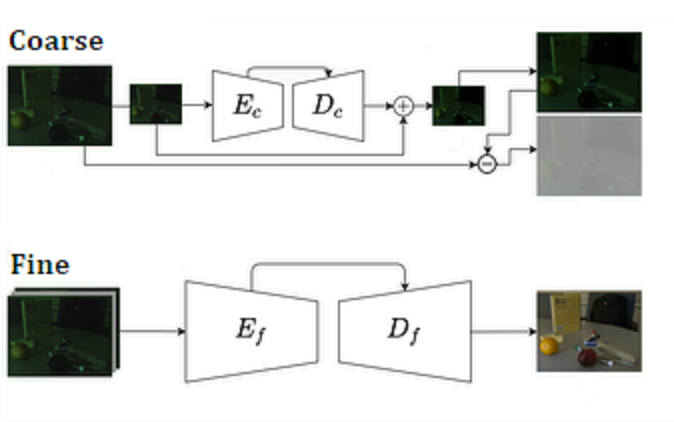
Coarse сеть берёт на вход уменьшенную вдвое по осям фотографию, прогоняет её через пару энкодер-декодер и получает на выходе, уменьшенную вдвое, относительно исходной, фотографию, но уже улучшенную (осветлённую) и избавленную от шума. Теперь то, что получилось увеличиваем до размеров исходной фотографии и, в принципе, заканчивать можно уже здесь - в некотором смысле мы получили то, что хотели, несколько “замыленный” вариант, но если взглянуть на картинку в начале результат работы Coarse сети уже выглядит весьма не плохо.
Теперь используя полученную фотографию, авторы выделяют “шум” - вычитают из исходной фотографии восстановленную. И запускают вторую сеть - Fine. На вход Fine сети отправляется исходное (темное) изображение, “шум” и изображение, сгенерированное Coarse сетью. Fine сеть это опять пара энкодер-декодер, которая генерирует уже вполне приличную осветлённую картинку. На этом, первый этап закончен.
Coarse и Fine сети тренируются на SID наборе, который содержит серию темных снимков и референсный снимок с длинной выдержкой, таким образом получается тренировать сети в supervised варианте. В качестве штрафной функции авторы используют комбинацию обычной L1 входного и выходного изображений и штрафа за контекст. Штраф за контекст это оценка разницы (в статистическом смысле) выхода от слоёв натренированной VGG сети на двух сравниваемых изображениях.
Наконец, мы добрались до восстановлению по серии снимков. Итак у нас есть несколько темных снимков, а мы хотим получить один светлый. Вначале, к каждому из темных снимков мы применяем Coarse сеть. Теперь для каждого темного снимка у нас есть еще и “шум”, а так же улучшенная хоть и заблюренная фотография. И вот весь этот набор мы и заводим в еще одну U-Net подобную сеть аналогичную Fine (даже весами инициализируем от Fine сети).
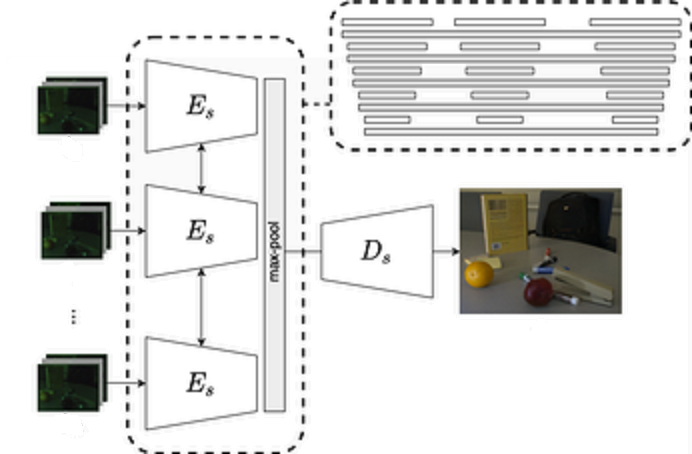
Через энкодер-часть мы прогоняем все снимки (фактически как некий batch). А вот декодер у нас уже всего один, при этом, поскольку это U-Net, на декодер мы должны отдать не только выход с последнего слоя, но и выходы с промежуточных слоёв энкодера. Это и делаем, но поскольку энкодеров теперь много, а декодер один и надо как-то выбирать, то выбираем очень просто - используем max pooling по нулевой оси (т.е. по оси батча) на выходах энкодеров. Судя по представленным в статье фотографиям - серия фоток действительно полезна с точки зрения улучшения качества.
Кстати для статьи есть код под Tensorflow причем такой как я люблю, без лишних кружавчиков, зато понятный.