Детектирование по нескольким камерам, с проектированием особенностей
Допустим, у нас есть некая местность (например, площадь), которая снимается синхронно несколькими камерами с разных точек. И мы хотим по набору фотографий получить карту (вид сверху) с расположенными на площади объектами (в данной статье речь идёт о прохожих).

Авторы предлагают простой и понятный подход - натренировать большую свёрточную сеть.
Итак, у нас есть набор фотографий, а для камер калибрационные матрицы и позиция, нам надо получить вид сверху и отметить на нём людей. Детектирование по одной фотографии не сработает, часть прохожих может быть перекрыто или не попадать в область видимости камеры. Поэтому надо детектировать на всех фотографиях и как-то объединять результат. Авторы, предлагают объединять не результаты детектирования, а features, полученные от свёрточных слоёв, и потом на этом объединении тренировать еще одну сеть, которая и выдаст нужный результат. Т.е. схема выглядит следующим образом:
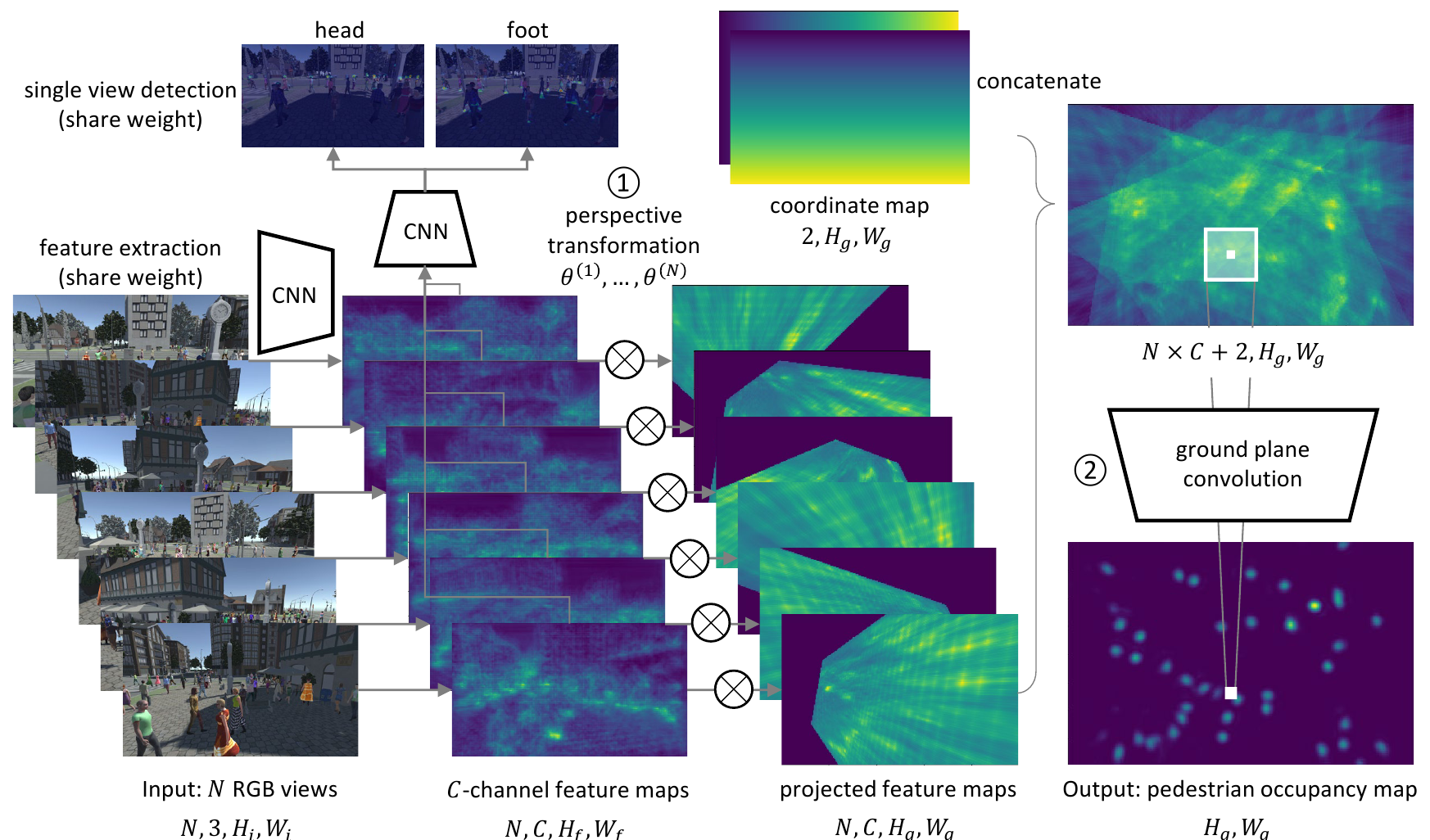
-
Фотографии подаются на вход свёрточной нейроннной сети (веса сети одни и те же для всех камер). Авторы в качестве такой сети используют ResNet18, заменяя последниии три слоя со stride большим 1, на dilated слои, чтобы не терять разрешение фотографии. На выходе такой сети получается для каждой фотографии, набор особенностей - тензор размера Wf * Hf * C.
-
Поскольку матрица калибрации камеры известна, то точку изображения (или точку набора особенностей) можно репроектировать в прямую в трехмерном пространстве. Беря на этой прямой точку, соотвествующую координате z = 0, авторы репроектируют набор особенностей от каждой фотографии на плоскость земли. Заполняя нулями те области, где проекция отсутствует и объединяя результаты от всех фотографий, получается новый тензор размера Wg * Hg * (C * N), здесь N - количество камер. К этому тензору прекрепляют еще два слоя, заполненные просто горизонтальной и вертикальной коордиантами точек (про пользу такого добавления есть крайне забавная статья An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution, которую я почему то упустил, и ее непременно надо будет не забыть разобрать).
-
Полученный на шаге 2 тензор размера Wg * Hg * (C * N + 2) подаётся на вход следующей свёрточной сети, которая уже и сформирует нам двумерный выход Wg * Hg с вероятностями наличия объекта в каждой точке.
-
Теперь осталось отрезать по порогу (авторы используют p = 0.4) и всё что выше порога объеденить при помощи NMS алгоритма.
Тренировка
Штрафная функция состоит из двух слагаемых.
-
По GT данным строится карта расположения объектов: черная картинка на которой позиции объектов размечаются белыми точками и размываются с гауссовским ядром. Первое слагаемое штрафной функции - это просто L2 норма между полученной таким образом картинкой и картой вероятностей с выхода сети.
-
Чтобы получать хорошие features дополнительно на том же features extractor будем тренировать детектор пешеходов (два: один на “головы” другой на “ноги”). Добавим еще одну свёрточную сеть генерирующую по features с фотографии две “heat map”: для “голов” и “ног” пешеходов. Для каждой камеры получим сумму из двух L2 норм между размеченными на фотографии частями пешеходов и выходом с соответствующей детектирующей сети. Взяв среднее арифметическое по всем камерам добавим результат вторым слагаемым в штрафную функцию.
Для тренировки авторы соорудили синтетический датасет MultiviewX, используя движок Unity (6 камер, 1080х1920, площадь: 16 метров на 25 метров).
Для тестирования использовали Wildtrack (7 камер, 1080х1920, 12 на 36 метров).
Исходный код, датасет и красивые движущиеся картинки можно посмотреть на GitHub