Быстрое детектирование объектов на сжатых jpeg изображениях
Авторы статьи (не они первые, на самом деле) задались вопросом, нельзя ли построить такой детектор объектов, который получал бы на вход изображения кодированные jpeg-кодеком и не распаковывая (или почти не распаковыя - не делая обратное DCT преобразование) искал бы на этом изображении объекты.
Вопрос вполне адекватный, действительно, информации, что в распакованной картинке, что в запакованной одинаковое количество, так почему бы нет. Понятно, что подавать непосредственно jpeg данные - дело практически наверняка бесполезное, и авторы решают всё таки расжать jpeg, но не до конечного изображения, а только до коэффициентов DCT. Причем, если обычно при кодировании в jpeg мы используем цветовое пространство YCbCr с так называемым отношением $4:2:0$, т.е. Y плоскость такого же размера как исходное изображение, а Cb и Cr плоскости уменьшены вдвое по обеим осям, то в данной статье авторы несколько упрощают ситуацию и используют отношение $4:4:4$ т.е. все три плоскости имеют такой же размер как и изображение. А значит и коэффициентов DCT преобразования из jpeg получаем столько же сколько исходных пикселей.
Авторы хотят попробовать натренировать SSD детектор с VGG-16 в качестве features extractor. Подход такой: SSD берёт отклики начиная с определённого слоя свёрточной части сети, вот все слои до него (т.е. блоки 1, 2 и 3 VGG сети), авторы выкидывают и заменяют на свёрточный слой с ядром $8 \times 8$ и шагом $8$ (здесь на входе DCT блоки разложены по исходному изображению, заменяя соответствующие блоки пикселей). В нормальном VGG-16 входное изображение $300 \times 300 \times 3$ прогоняется через 7 свёрточных слоёв и 3 maxpool-инга, и в результате на входе 4-го блока получается тензор размера $38 \times 38 \times 512$. В случае DCT такой тензор делает один свёрточный слой. Если говорить о скорости, то авторы сэкономили уже здесь.
На самом деле подход, на мой взгляд, достаточно странный. Т.е. при чем тут свёртки $8\times8$ - не понятно. Т.е. понятно, и размер ядра свёртки и шаг, когда блоки разложены так как разложены, ведь двумерная свёртка интересна для учёта корреляции соседних пикселей, а здесь у нас внутри блока эта корреляция еще как то возможно есть, но только явно не та, что хорошо выявляется двумерной свёрткой, а между блоками всё уже сложнее, у нас ведь не пиксели, а коэффициенты при частотах DCT.
Логично было бы, на мой взгляд, соорудить тензор с размером $\lceil W / 8 \rceil \times \lceil H / 8 \rceil \times 8 \cdot 8 \cdot 3$. Здесь каждая из плоскостей в $8 \times 8 = 64$ раза меньше плоскости исходного изображения, и представляет из себя амплитуды конкретной частоты, либо для яркости, либо для цветности. И вот тут никто не запрещает использовать обычные свёрточные слои и не обязательно в единичном экземпляре.
Правда надо отметить еще один момент вытекающий из того как “сжимает” jpeg: высокие частоты обычно зануляются при квантизации, и, соответственно, часть плоскостей тензора будут состоять полностью или практически полностью из нулей. Возможно, поэтому авторы решили “сворачивать” коэффициенты одного блока.
Возвращаемся к статье. Прежде чем тренировать SDD детектор, обычно сеть которую планируют использовать в качестве feature extractor тренируют как классификатор, используя большой датасет ImageNet. VGG-16 для обычных RGB картинок есть уже натренированные, а вот обрезанный вариант для DCT на входе - естественно отсутствует, поэтому авторы тренировали его сами. Тренировали они его либо сразу с нуля (From Scratch), либо, как рекомендуется в исходной статье по VGG, вначале натренировав короткую сетку, а потом, инициализировавшись весами из нее, дотренировывать VGG-16 (вариант FA - From VGGA). Еще, для сравнения, брались результаты сети VGG-16, которую тренировали авторы статьи про VGG (назовём её VGG official).
Результаты приводятся для тестового датасета в случае VGG official и для валидационного, потому что тестового у авторов не было, для остальных.
Сеть | Пространство | top-1 accuracy | top-5 accuracy |
-----------------------------------------------------------------
VGG official | RGB | 75.6 (test) | 92.8 (test) |
VGG | RGB | 49.8 (val) | 74.8 (val) |
VGG (FS) | DCT | 40.3 (val) | 65.1 (val) |
VGG (FA) | DCT | 42.0 (val) | 66.9 (val) |
-----------------------------------------------------------------
Честно говоря, когда смотрим на таблицу, навыки авторов статьи по тренировке классификатора вызывают определенные сомнение, но они пишут, что не сильно то и хотелось, классификатор им не нужен, а нужно только инициализировать веса для детектора. После этого они тренируют детектор на датасете Pascal VOC, используют 2007 и 2007+2012 версии, тренируются на объединении тренировочного и валидационного наборов, тестируются на тестовом наборе 2007.
Сеть | тренировочный датасет | mAP (test 2007) |
-------------------------------------------------------
SSD official | 07+12 | 74.3 |
SSD RGB | 07+12 | 59.0 |
SSD DCT | 07+12 | 47.8 |
-------------------------------------------------------
SSD official | 07 | 68.0 |
SSD RGB | 07 | 50.3 |
SSD DCT | 07 | 39.2 |
-------------------------------------------------------
Очевидно, что в варианте с DCT имеется существенная просадка по качеству даже относительно варианта SSD RGB натренированного авторами, отставание от официального варианта просто дичайшее.
Еще авторы вместо PASCAL VOC (где, напомним, 20 различных классов), берут свой датасет ACTEMIUM где только три класса: машина, мотоцикл и грузовик. И тренируют-тестируют детектор на этом наборе:
Сеть | тренировочный датасет | mAP |
-------------------------------------------------------
SSD official | ACTEMIUM | 82.3 |
SSD RGB | ACTEMIUM | 77.8 |
SSD DCT | ACTEMIUM | 74.6 |
Отставание сократилось, однако, DCT вариант всё равно хуже.
Авторы предположили, что падение качества детектирования неравномерно и зависит от размера объектов и построили гистограмы:
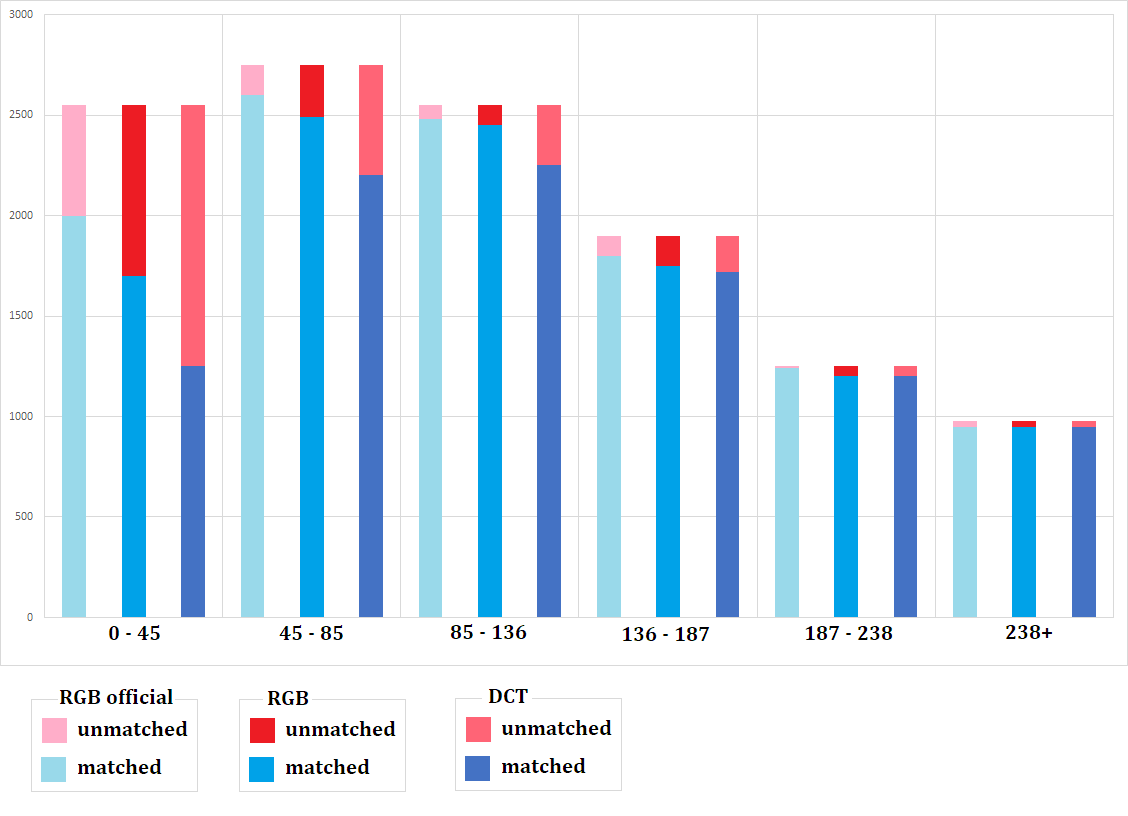
DCT вариант детектора на “маленьких” объектах сильно отстаёт, но на больших показывает результаты практически такие же как и RGB варианты.
Наконец, то из-за чего всё затевалось - скорость работы. Авторы тестировали детектор на Nvidia GTX 1060 и выяснили, что вариант с DCT в 2.05 раза быстрее. И это, если я правильно понял, только скорость вывода сети, а там еще за счет не применения обрбатного косинус преобразования, скорость должна повышаться.
Выводы
-
Можно тренировать в DCT пространстве вместо пространства картинок и получать достаточно приемлимые результаты. Оно и понятно, для маленьких объектов и не должно быть хороших фич при той структуре сети, которая заявлена.
-
По моим ощущениям, можно сильно улучшить качество, если подойти к делу более аккуратно, т.е. отрезание 7 свёрточных слоёв, оно, заведомо ускорит работу сети, но возможно более тонкая настройка позволила бы при приросте в скоросте не потярять настолько сильно в качестве (т.е. даже от их же RGB варианта - падение ~11%, а это существенно)