Изображения как набор слов 16 х 16.
Если здесь attention модель применялась “локально” и фактически self-attention преобразование служило заменой стандартной свёртки, то сегодня посмотрим на статью, в которой авторы попытались максимально перенести подход, предложенный для решения задачи перевода в компьютерное зрение.
На самом деле, первым делом есть смысл разобраться с исходной статьёй об attention модели. Для этого порекомендую чудесный разбор от нашего зарубежного товарища, с картиночками и крайне подробный. Когда с базовой концепцией разобрались, новую статью можно понять за одну картинку:
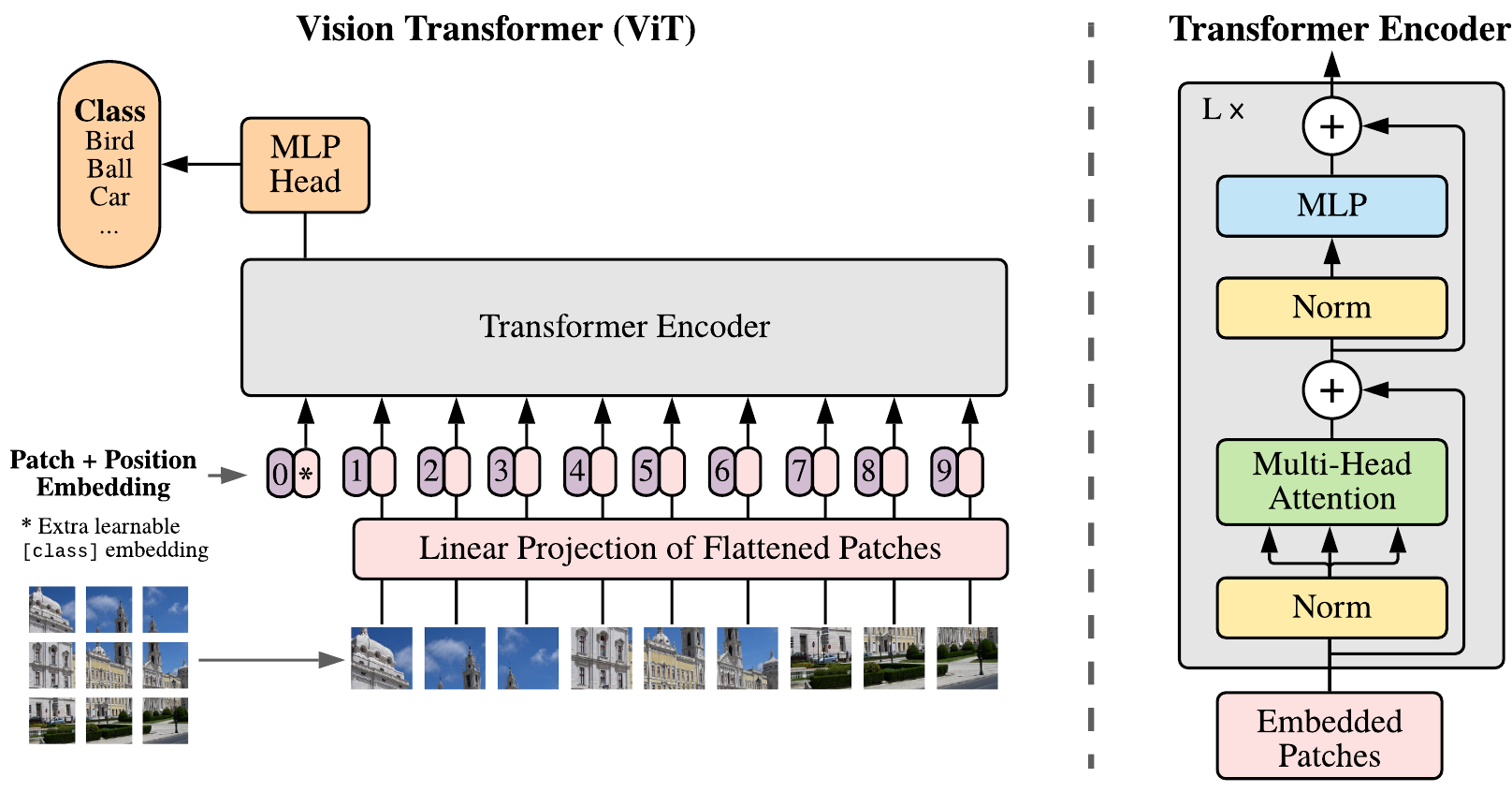
Т.е. модель полностью повторяет transformer применяемый для переводов текстов. Только вместо слов из предложения, которое хотим перевести, (слова у нас не просто кодированы one-hot по словарю, а вначале вложены в некоторое векторное пространство при помощи word2vec преобразования) на вход подаются патчи на которые режим картинку. Причем, патчи тоже не плохо вначале прогнать через какую-нибудь сверточную сетку типа ResNet и соответственно в transformer отдавать уже не сами пиксели, а наборы откликов.
Судя по статистике, авторы обещают повышение качества на 1-1.5%, но зато снижение времени тренировки до 4-х раз.