GANcraft. 3D рендеринг Minecraft миров, обучение без учителя
В данной статье предлагается механизм генерации фотореалистичных изображений 3Д мира созданного в таких программах как Minecraft, т.е. на вход поступает: “крупноблочное” 3Д представление мира, точка съемки и стиль генерации (например, зима-весна-лето, утро-день-вечер и т.п.) - на выходе “фотография”. Важно, отметить, что фотографии нормально склеиваются, т.е. одно место снятое с разных точек генерирует консистентные изображения.
Генератор на самом деле получается удачным объединением двух работ: Semantic image synthesis with spatially-adaptive normalization. - в ней описана сеть, которая может генерировать фотореалистичное изображение из семантической разметки. И NeRF, который в прошлый раз разбирали.
Сеть SPADE используется, чтобы генерировать псевдо-grountruth данные. Выбрав случайную позицию и фокальное расстояние камеры вначале генерируется “фотография” трёхмерного крупноблочного мира, которая представляет из себя фактически семантическую разметку. Затем случайным образом задаётся стиль и из семантической разметки сеть генерирует фотореалистичное изображение.

Из NeRF берётся способ представления трёхмерных данных. Minecraft мир состоит из блоков (т.н. вокселей), большая часть из которых это пустое пространство, но так же есть земля, вода, деревья и т.п. Если $\mathcal V = \{V_1, V_2, …, V_K\}$ все не пустые блоки, а $\{l_1, l_2, …, l_K\}$ соответствующие им типы блоков, то поле излучения описывается следующей функцией:
\[F(p, z) = \begin{cases} F_i(p, z), & p \in V_i, \, i \in {1, ..., K}\\ (0, 0), & иначе \end{cases}\]Как и в NeRF - на выходе функции пара: вектор и значение прозрачности-плотности, но в отличии от NeRF вектор это не цвет, а набор откликов. Функция собирается из $F_i(p,z)$ - каждая описывает своё поле излучения внутри не пустого блока $V_i$, для пустого блока $F$ возвращает нулевой вектор откликов и нулевую плотность. $z$ здесь определяет стиль конечного изображения (день-ночь, лето-зима и т.п.).
Отдельные функции для блоков представляются в виде:
\[F_i(p,z) = G_{\theta}\left(g_i(p), l_i, z\right) = (c(p, l(p), z), \sigma(p, l(p)))\]$G_{\theta}$ сеть из полносвязных слоёв, которая генерирует набор откликов $c$ и плотность $\sigma$ для позиции $p$. При этом отклики $c$ зависят еще и от стиля $z$, а плотность от стиля не зависит. $g_i(p)$ - это код позиции $p$, а $l_i \equiv l(p)$ - тип блока в котором находится позиция $p$.
Чтобы получить кодированное представление позиции $g_i(p)$, каждой вершине каждого блока приписывается тренируемый вектор, а вектор $g_i(p)$ получается интерполяцией векторов вершин блока в котором расположена $p$ (размер блока предполагается $1 \times 1 \times 1$ и оси блока сонаправлены координатным осям). Важно отметить, что смежные блоки имеют общие вершины и следовательно общие вектора, кодирующие координаты этих вершин, а это в свою очередь приводит к гладкости откликов сети $G_{\theta}$ при переходе через границу блока.
Небо кодируется отдельной сетью из полносвязных слоёв: $c_{sky} = H_{\phi}(v, z)$. В данном случае, $z$ снова стиль, общий с тем, который передаётся в сеть $G_{\theta}$, а $v$ - направление луча. Поскольку небо в некотором смысле формирует “задник” картинки, то считается, что оно полностью не прозрачно.
Объёмный рендеренг, описывается аналогично тому как это было в статье по NeRF:
\[C(r,z) = \int_0^{+\infty}T(t)\cdot\sigma\left(r(t), l\left(r(t)\right)\right)\cdot c\left(r(t), l\left(r(t)\right), z\right)dt + T(+\infty)\cdot c_{sky}(v,z)\]а $T(t) = \exp\left(-\int_0^t\sigma\left(r(s)\right)ds\right)$ - накопленная непрозрачность вдоль луча на расстоянии $t$, а $C(r,z)$ - в данном случае не цвет, а вектор откликов. Интегралы решаются примерно теми же методами, что были описаны для NeRF и в результате мы имеем трехмерный тензор откликов, который поступает на вход ещё одной, уже свёрточной сети, которая и генерирует окончательную картинку, причем в эту сеть снова подаётся стиль $z$
Полный фреймворк выглядит следующим образом:
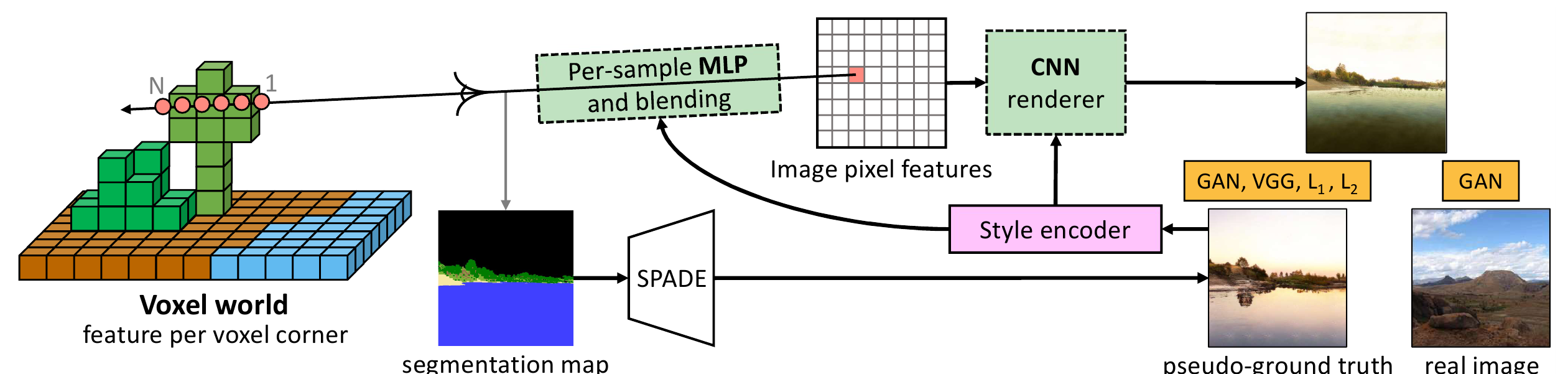
Сети штрафуются за ошибку между полученным изображением и псевдо-groundtruth, который сеть SPADE сгенерировала на базе семантической разметки. Плюс штраф GAN составляющей, когда сгенерированное изображение помечается как фейковое, а псевдо-groundtruth и настоящая фотография как реальные.
Исходники на данный момент не выложили (но обещают), зато на сайте можно насладиться красивыми видео, сгенеренными сеткой описанной в статье.