Улучшение передачи знаний с использованием ассистента учителя
В прошлый раз разбирался с передачей знаний от большой нейронной сети (учителя) к маленькой нейронной сети (ученику). В статье, разбираемой сегодня, авторы выдвигают идею, которую можно описать примерно следующим образом: слишком умный учитель не может хорошо обучить слишком слабого ученика, поэтому такому учителю нужен ассистент. Т.е. передача знаний от большой нейронной сети к очень маленькой, будет идти лучше, если мы вначале натренируем промежуточную сеть: ассистента учителя (teacher assistent) в которую передадим знания от учителя, а уже эта средняя сеть будет использоваться для тренировки совсем малой нейронной сети-ученика.
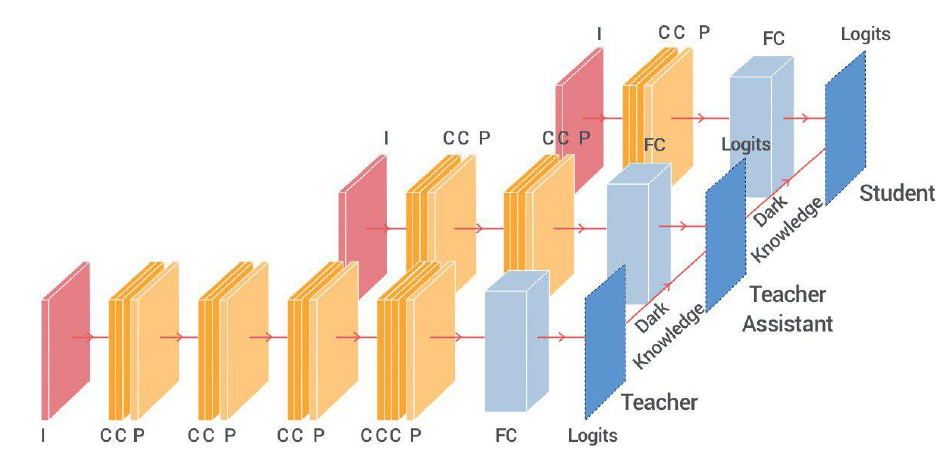
Авторы начинают с того, что берут датасеты CIFAR-10 и CIFAR-100 и обучают на них несколько свёрточных нейронных сетей - учителей с разным количеством свёрточных слоёв: 4, 6, 8, 10 (используется архитектура типа VGG, т.е. пара свёрточных слоёв, потом max-pooling, снова пара свёрточных слоёв, и т.д., наконец, полносвязный слой, на выходе которого logits). Очевидно, в данном случае с ростом количества слоёв растёт и точность сети-учителя на тестовых данных. Взяв теперь в качестве ученика сеть из 2 свёрточных слоёв, авторы пытаются передать ему знания от каждого из учителей.
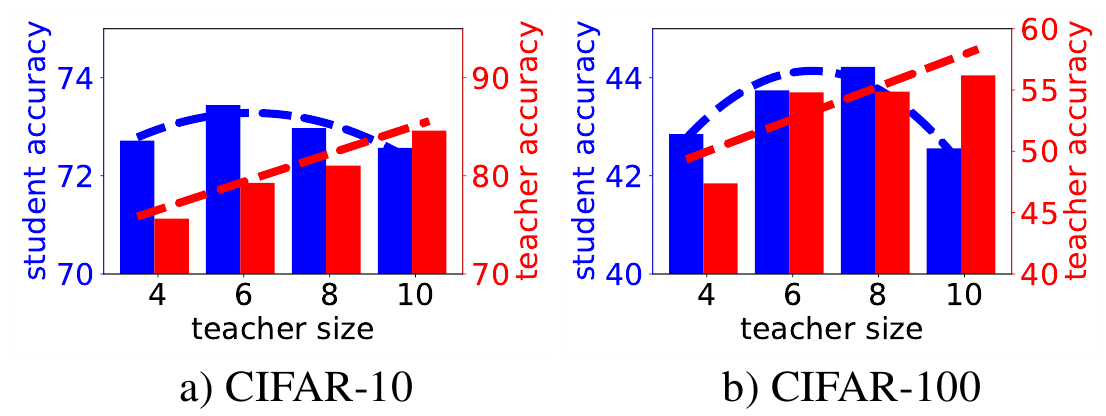
Из графиков видно, что качество ученика растёт с ростом качества учителя, но лишь до определённого момента, после чего начинает падать.
Авторы предлагают для объяснения полученных эмпирических данных рассмотреть три фактора:
-
Если качество сети-учителя растёт, то эта сеть должна лучше обучать ученика.
-
Если сеть-учитель усложняется, то сеть-ученик может быть не достаточно приёмистой, чтобы суметь воспринять передаваемые знания.
-
С ростом внутренней сложности сеть-учитель начинает чётче разделять данные на классы, а значит её оценки (logits) становятся менее сглажены, а собственно, сглаженность оценок есть фактор, который и работает в knowledge distillation подходе.
Первый фактор приводит к росту, а второй и третий наоборот к уменьшению, качества сети ученика при обучении от более сложной сети учителя.
Я тут от себя замечу, что фактор номер один крайне противоречив, т.е. наилучшее качество классификации - это просто брать GT данные из датасета, однако, именно их размытие и позволяет лучше тренировать ученика, а вот растёт ли с ростом качества классификации, качество поиска схожести классов - вопрос сложный и как раз фактор номер три, говорит, что скорее всего, если и растёт, то только до определенного значения сложности сети.
Далее авторы проводят обратный эксперимент: берут в качестве учителя сеть размера 10 (размер - кол-во свёрточных слоёв) и обучают с её помощью учеников размера 2, 4, 6 и 8. На графиках отображён прирост качества сети-ученика, натренированной с передачей знаний от сети-учителя размера 10, относительно просто тренировки такой сети-ученика на соотвествующем датасете.
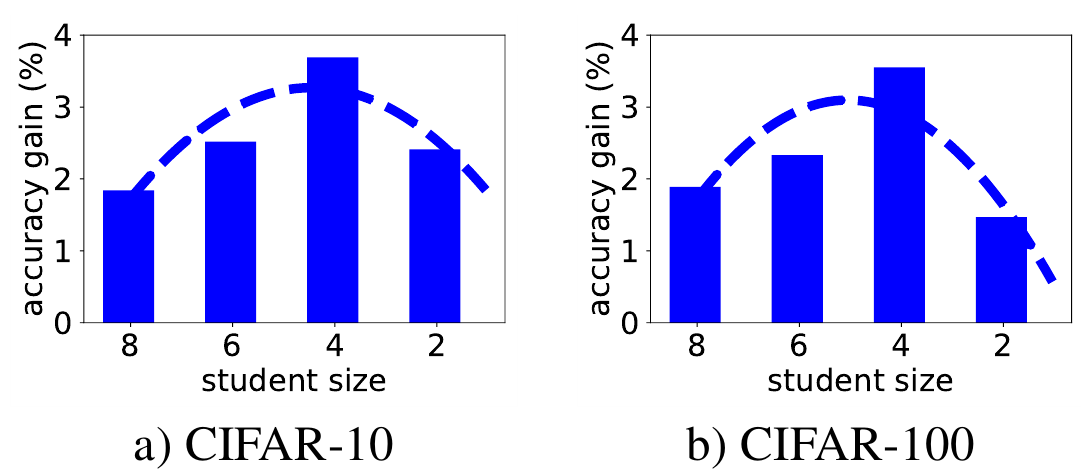
Таким образом, передача знаний от очень большой сети к очень маленькой оказывается не вполне эффективной. Поэтому, авторы статьи предлагают использовать промежуточную сеть - помошник учителя (teacher assistant), натренируем вначале эту промежуточную сеть, используя сеть-учитель, а затем натренируем ученика, используя в качестве источника знаний помошника учителя (teacher assistant knowledge distillation (TAKD)).
В качестве доказательства, что такой подход работает, авторы проверяют его на CIFAR-10 и CIFAR-100 на двух типах свёрточных сетей: VGGlike и ResNet, и дополнительно на ImageNet датасете на ResNet моделе.
Модель | Dataset | NoKD | BLKD | TAKD |
----------------------------------------------------
VGG | CIFAR-10 | 70.16% | 72.57% | 73.51% |
| CIFAR-100 | 41.09% | 44.57% | 44.92% |
----------------------------------------------------
ResNet | CIFAR-10 | 88.52% | 88.65% | 88.98% |
| CIFAR-100 | 61.37% | 61.41% | 61.82% |
----------------------------------------------------
ResNet | ImageNet | 65.20% | 66.60% | 67.36% |
----------------------------------------------------
- NoKD - тренировка ученика, без учителя, только по набору данных
- BLKD - передача знаний от учителя к ученику непосредственно (baseline knowledge distillation)
- TAKD - передача знаний от учителя к ученику, через помошника
Для CIFAR используем следующие размеры сетей:
- VGG - ученик размера S = 2, помошник учителя TA = 4 и учитель T = 10
- ResNet - S = 8, TA = 20, T = 110
Для ImageNet, ResNet - S = 14, TA = 20, T = 50
Из таблицы видно, что вариант с помошником (TAKD) во всех случаях даёт наибольшую точность.
Следуюший вопрос, а какого размера должна быть промежуточная сеть, чтобы передать знания максимально эффективно? Чтобы это выяснять, авторы проводят эксперименты с различными размерами (не всеми возможными, но достаточно, для получения оценок). Первый набор экспериментов это VGGlike сеть на датасетах CIFAR, знания передаются от сети размера 10 к сети размера 2, через промежуточную сеть размера TA:
Модель | Dataset | TA = 8 | TA = 6 | TA = 4 |
----------------------------------------------------
VGG | CIFAR-10 | 72.75% | 73.15% | 73.51% |
| CIFAR-100 | 44.28% | 44.57% | 44.92% |
----------------------------------------------------
Второй набор экспериментов для ResNet варианта сети на тех же датасетах, с учителем размера T = 110 и учеником S = 8
Модель | Dataset | TA = 56 | TA = 32 | TA = 20 | TA = 14 |
--------------------------------------------------------------
ResNet | CIFAR-10 | 88.70% | 88.73% | 88.90% | 88.98% |
| CIFAR-100 | 61.47% | 61.55% | 61.82% | 61.50% |
--------------------------------------------------------------
Дальше авторы делают интересное, но как мне кажется, слабо обоснованное предположение. Рассмотрим следующий график, для VGGlike сетей на CIFAR-10 и CIFAR-100:
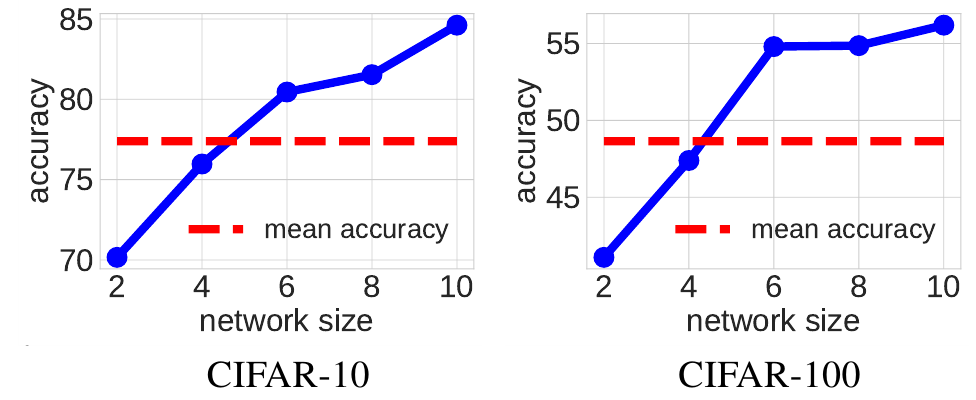
синим здесь показано качество сетей разных размеров, натренированных только на датасете без KD, а красная черта это среднее арифметическое значений качества сети размера 10 и сети размера 2. Авторы пишут: “смотрите, среднее находится на уровне сети размера 4, и сеть этого размера, использованная в качестве помошника даёт наилучшее качество при тренировки ученика, похоже именно так и надо выбирать размер помошника”. Этот вывод подтверждает и график для варианта с ResNet сетью:
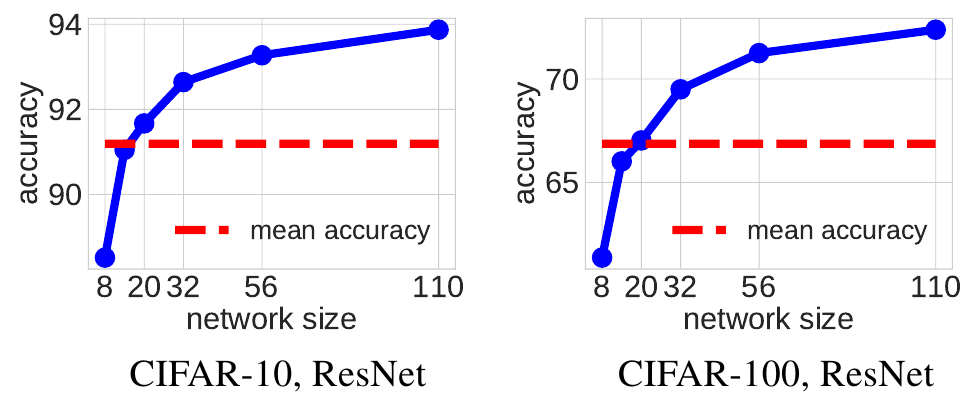
Здесь для CIFAR-10 средняя проходит через сеть размера TA = 14, а для CIFAR-100 - через сеть размера TA = 20 и действительно, при таких размерах помошника мы получаем максимальное качество при передаче знаний от учителя ученику.
Однако, во-первых, не понятно как это обосновать теоретически. Во-вторых, чтобы получить таким образом оценку размера помошника надо натренировать достаточно большое число сетей промежуточного размера, можно сразу решать задачу передачи знаний с разными размерами помошника и выбрать лучший вариант ученика.
Наконец, последний вопрос: а что если вместо одного помошника, использовать серию, последовательно уменьшая размер? Авторы статьи поставили эксперимент для ответа и на этот вопрос. Результаты этого эксперимента сведены в следующую таблицу:
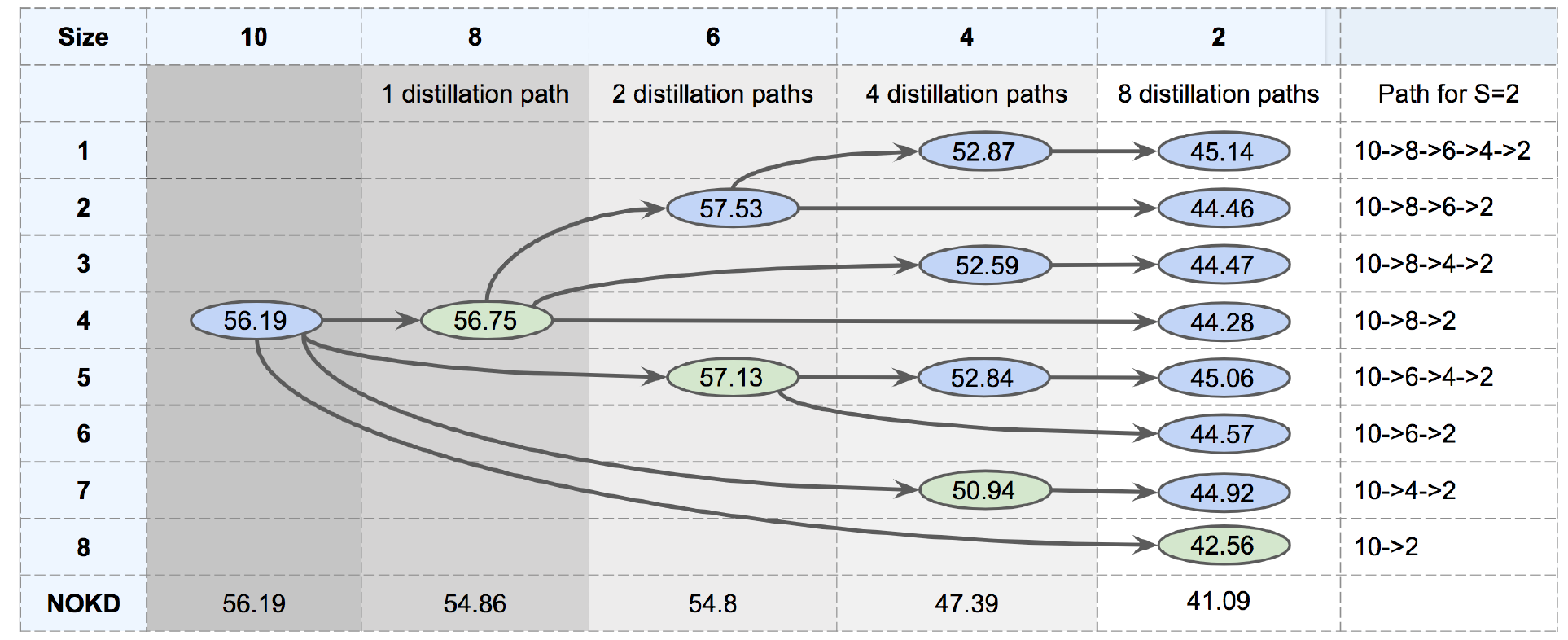
Надо отметить, что из таблицы видно, что лучший результат получается при последовательной тренировки помошника всё меньшего размера, а резкие переходы снижают результирующую точность.