YOLO, SSD и другие.
Мы уже рассматривали два современных подхода к детектированию объектов на изображении при помощи свёрточных нейронных сетей: R-CNN, FastRCNN, FasterRCNN и Overfeat. Самое время разобраться с еще одним классом детекторов в который входят: YOLO, SSD и т.п.
Содержание
Введение
Когда деревья были большими, а нейронные сети в компьютерном зрении не применялись так широко (а было это всего лет 6-7 назад), для детектирования объектов на изображении использовался достаточно простой подход. Тренировался бинарный классификатор, который мог определить есть на картинке (обычно крайне не большого размера, например, $32 \times 32$) объект определенного типа (например, лицо) или нет. После того как классификатор натренирован, по изображению запускали скользящее окно (sliding window) и для каждого прямоугольника выдернутого скользящим окном применяли этот бинарный классификатор. Поскольку на одном изображении объекты могут быть и маленькими и большими, то либо надо было запускать окно разных размеров, либо (что происходило чаще) из исходного изображения строили пирамиду разных масштабов, и запускали скользящее окно по каждому слою пирамиды. Основная задача была найти такие особенности (features), которые бы позволили натренировать хороший бинарный классификатор (начиная от классичеких Haar features из [1] до ICF, ACF и др. со всеми промежуточными остановками).
В поиске хороших особенностей скачок произошёл с внедрением свёрточных нейронных сетей, тогда же дело пошло на лад и с задачей детектирование. Например, уже в 2013 появилась статья [2], про Overfeat сеть, где подход со скользящим окном обобщался на свёрточную нейронную сеть, применяемую в качестве классификатора.
Дальше появилась линейка R-CNN, FastRCNN, FasterRCNN в статьях [3], [4], [5], и расширения этого подхода (например, для сегментации элементов в Mask R-CNN ). Здесь, вместо скользящего окна, использовался предварительный детектор для поиска объектов (для R-CNN это был selective search, а для FasterRCNN эту роль выполняла RPN подсеть), а затем сеть определяла класс объекта (при этом специально заводился “background” класс, чтобы отбрасывать плохих кандидатов пришедших от предварительного детектора) и уточняла его прямоугольник. Результаты были отличные, разве что скорость даже FasterRCNN, не смотря на название, была не то чтобы очень высока.
Наконец, третий подход появился в статье [6] - YOLO (You Only Look Once), потом продолжился в [7] - SSD (Single Shot Detector), усовершенствовался авторами исходной статьи в [8] (YOLO 9000) и [10] (YOLOv3), а также продолжался в [9], где была предложена сеть RetinaNet, и несколько изменённый взгляд на штрафную функию, который позволил избавиться от процедуры поиска сложных негативов (hard negative mining)
Для ускорения процесса детектирования в этих работах предлагается, не искать объекты бегая по изображению (скользящим ли окном или каким-то вариантом поискового алгоритма), а выбрать некоторое фиксированное количество прямоугольников и для каждого проверить наличие в нем объекта, и, если объект найден, определить какого он класса и уточнить bounding box. Например, в [6] на картинку просто накладывается решетка и в каждой клетке этой решётки проверяется нет ли там центра какого-нибудь объекта?
Вот об этом подходе и поговорим в хронологическом (по возможности) порядке.
YOLO
Итак, авторы [6] предложили, вместо того, чтобы искать объекты и потом проверять их классификатором, просто разбить картинку равномерной сеткой $S \times S$ и для каждой ячейки выдавать есть ли в ней центр какого-то объекта, какого он класса и его точный прямоугольник. А именно для каждой ячейки отдавать:
-
Набор из $B$ пятёрок вида: $\langle x, y, w, h, p\rangle$, здесь $x, y$ - относительные координаты центра объекта внутри ячейки (т.е. отсчитываются от левого верхнего угла ячейки $(0, 0)$, и до правого нижнего угла ячейки $(1, 1)$). $w, h$ - размеры объекта (объект не обязан лежать целиком внутри ячейки, размеры - числа от $0$ до $1$, задаются относительно размеров исходного изображения). Последнее число $p$ - это уверенность сети, что объект есть и его прямоугольник задан правильно. Формально авторы говорят, что $p$ это вероятность наличия центра объекта в ячейке умноженная на IoU (пересечение делённое на объединение) областей реального объекта и предсказанного прямоугольника $x, y, w, h$.
-
$C$ вероятностей, по количеству классов объектов, которые мы детектируем, что объект с центром в данной ячейке принадлежит, соответствующему классу.
Тут надо отметить два нюанса:
Для каждой ячейки мы имеем несколько предсказанных прямоугольников и только один набор вероятностей принадлежности к классу.
Мы не добавляем класс для “нет объектов” - эту ситуацию должна решать вероятность, привязанная к bounding box, т.е. для ячейки возможна ситуация, когда у всех $B$ её пятёрок, уверенность $p = 0$, причём чаще всего так оно и есть, потому что ячеек много, а объектов на картинке чаще всего мало.
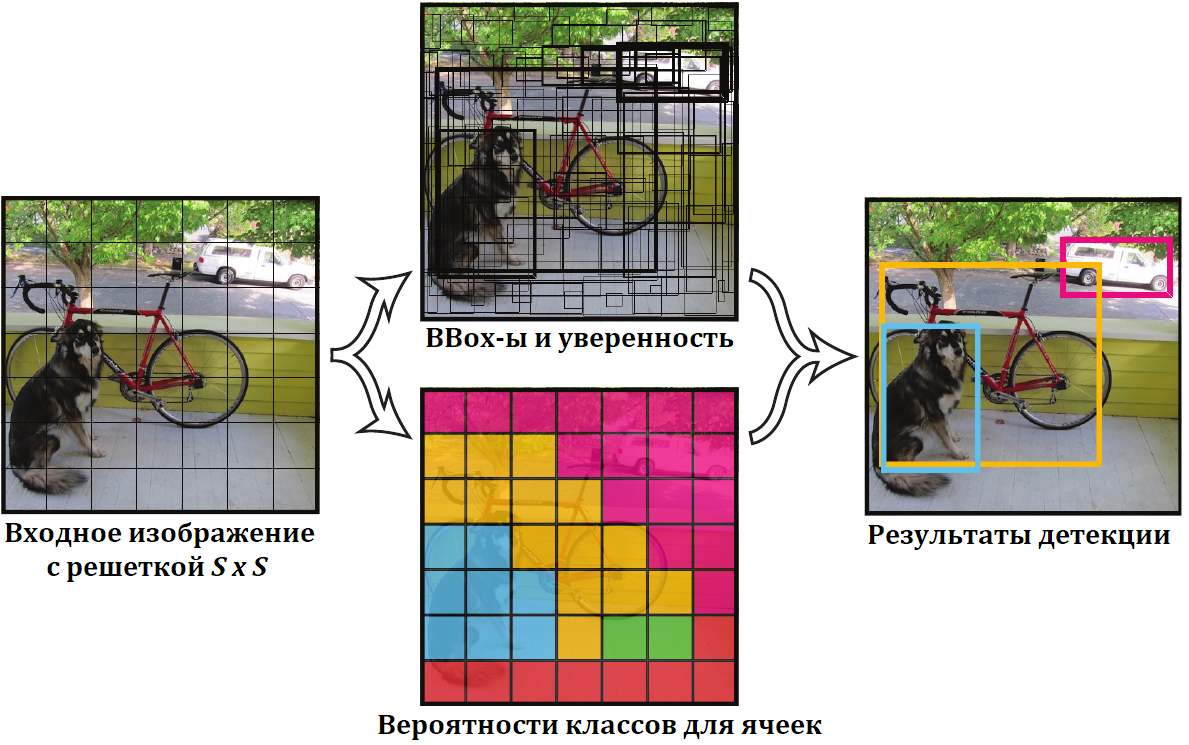
Итак, получая на вход изображение, на выходе сеть должна выдавать тензор размера $S \times S \times (B \cdot 5 + C)$. В общем виде, схема сети выглядит следующим образом:

Авторы предлагают:
-
подавать на вход изображения размером $448 \times 448$,
-
разбивать их при помощи решётки с $S = 7$,
-
для каждой ячейки выдавать $B = 2$, предсказанных прямоугольника,
-
так как в качестве датасета берётся Pascal VOC в котором размечено 20 классов, то $C = 20$.
Т.е. на выходе сети будет тензор $7 \times 7 \times 30$
В качестве базовой сети для выделения ососбенностей, авторы берут GoogLeNet с некоторыми упрощениями, и в двух вариантах: 24 свёрточных слоя или 9 для особо быстрого детектирования. На самом деле понятно, что подойдет любая свёрточная сеть хорошо выделяющая особенности и работающая с должной скоростью.
Тренировка YOLO
Тренировка происходит в два этапа. На первом этапе “feature extraction” часть сети тренируется на ImageNet датасете в составе классификатора на 1000 классов, которые размечены в ImageNet. При этом входная картинка берётся размером $224 \times 224$. На втором этапе тренируется непосредственно детектирующая сеть, а поскольку для детекции хорошо иметь разрешение побольше, на вход подаётся уже картинка размером $448 \times 448$. Свёрточные слои детектирующей сети инициализируются весами, натренированными на ImageNet и сеть дотренировывается на Pascal VOC датасете.
Датасет
Остановимся подробнее на том, как в данном случае выглядят размеченные данные для тренировки. Итак, у нас есть изображение на котором прямоугольниками заданы объекты и каждому объекту приписан свой класс.

Однако, сеть у нас выдаёт тензор $S \times S \times (B \cdot 5 + C)$ и значит эталонные данные есть смысл представить в каком-то похожем виде. Будем исходить из предположения, что в тренировочном датасете, два объекта на фотографии не могут иметь центр в одной ячейке (авторы статьи явно это не прописывают, но, судя по формуле для штрафной функции, они именно это предполагают, реализации, которые я видел, тоже с этим согласны, да и просто изображения у которых центры двух объектов попадают в одну ячейку встречаются крайне редко), тогда, нам достаточно будет для каждой ячейки прописать: есть ли в ней центр какого-то объекта и, если есть, описать этот объект.
Рассмотрим пример.
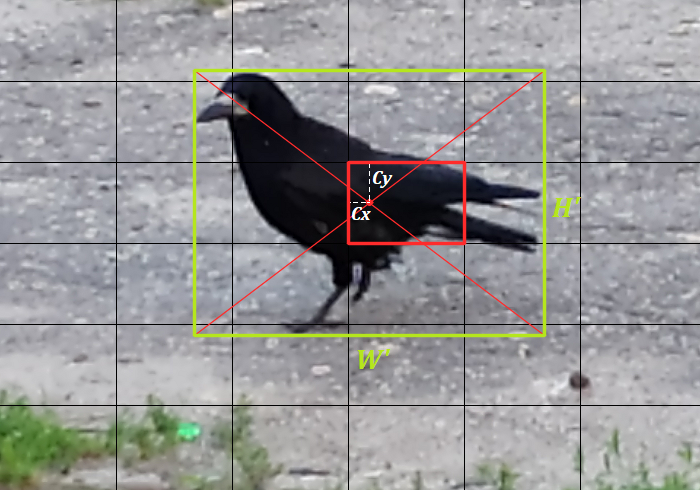
Обозначим размеры изображения $W, H$, возьмём сетку $S \times S$, размер ячейки в этом случае будет $W_c = W / S, H_c = H / S$. Центр нашей птицы (в системе координат изображения: $(C’_x, C’_y)$) попадает в ячейку $(3, 2)$, размеры объекта: $(W’, H’)$. Как мы помним, центр объекта нам нужен в координатах от левого верхнего угла ячейки, а это будет:
\[C_x = C'_x - 3 * W_c, \\ C_y = C'_y - 2 * H_c\]Раз объект на изображении один, то все ячейки кроме одной $(3, 2)$ будут содержать нули. А для ячейки, где центр нашей вороны, вместо нулей в тензоре будет:
-
Пятёрка $\langle \hat{x}, \hat{y}, \hat{w}, \hat{h}, 1 \rangle$:
\[\begin{aligned} \hat{x} & = C_x / W_c, \\ \hat{y} & = C_y / H_c, \\ \hat{w} & = W' / W, \\ \hat{h} & = H' / H \end{aligned}\] -
Вектор вероятностей для классов: $\hat{p} = (0,…,0,1,0,…,0)$ - с единицей на месте класса птицы и нулями на остальных.
Штрафная функция
Штрафная функция логичным образом разбивается на сумму штрафов по всем ячейкам изображения:
\[\mathcal{L} = \sum_{i = 1}^{S \cdot S} \mathcal{L}(i)\]Ячейки у нас двух типов: содержащие и не содержащие центр объекта, и штрафовать их надо по разному. Формализуем это различие и введем индикаторную функцию:
\[\chi_i = \begin{cases} 1, & i-я\; ячейка\; содержит\; объект \\ 0, & i-я\; ячейка\; не\; содержит\; объект \end{cases}\]здесь $i = 1,…,(S \cdot S)$.
Для ячеек в которых есть объект, обозначим его прямоугольник:
\[\hat{R}_i =(\hat{x}_i, \hat{y}_i, \hat{w}_i, \hat{h}_i)\]Здесь тоже прямоугольник задаётся относительными координатами центра внутри ячейки, а размер относительно размеров всего изображения.
При этом для каждой ячейки у нас $B$ предсказателей, каждый из которых выдаёт свой прямоугольник. Обозначим прямоугольник от $j$-го предсказателя в $i$-ой ячейке:
\[R_{ij} = (x_{ij}, y_{ij}, w_{ij}, h_{ij})\]Мы хотим выделить тот предсказатель, который лучше других определяет прямоугольник объекта, для этого введём еще один индикатор:
\[\chi_{ij} = \begin{cases} 1, & \chi_i = 1\; и\; j = \rm{argmax}_{j=1,...,B}\left(IoU(\hat{R}_i, R_{ij})\right)\\ 0, & в\; остальных\; случаях \end{cases}\]здесь $i = 1,…,(S \cdot S)$, и $j = 1,…,B$.
Теперь мы можем разобрать составляющие штрафной функции для ячейки.
Штраф за классификацию
Если ячейка содержит центр объекта, то сеть должна правильно предсказать класс этого объекта, поэтому первым слагаемым в штрафной функции ячейки будет штраф за классификацию:
\[\mathcal{L}_{class}(i) = \chi_i \cdot \sum_{cl \in classes} (p_i(cl) - \hat{p}_i(cl))^2\]$\chi_i$ - оставляет это слагаемое только для ячеек, где объект есть. $p_i(cl), cl = 1,…,C$ - предсказанная вероятность принадлежности объекта классу $cl$, $\hat{p}_i(cl)$ - единица для действительного класса в который размечен объект в ячейке, и ноль для всех остальных классов.
Тут несколько удивляет, почему $L^2$, а не кроссэнтропия, но вот так придумали авторы.
Штраф за прямоугольник
Если ячейка содержит центр объекта, то “лучший” предсказатель (тот у которого максимальный IoU предсказанного прямоугольника с размеченным) должен хорошо предсказать координаты центра и размеры прямоугольника, остальные предсказатели штрафовать не будем:
\[\mathcal{L}_{coord}(i) = \sum_{j=1}^{B} \chi_{ij} \cdot \mathcal{L}_{coord}(i, j)\]Штраф лучшему предсказателю задаётся как:
\[\mathcal{L}_{coord}(i, j) = (x_{ij} - \hat{x}_i)^2 + (y_{ij} - \hat{y}_i)^2 + (\sqrt{w_{ij}} - \sqrt{\hat{w}_i})^2 + (\sqrt{h_{ij}} - \sqrt{\hat{h}_i})^2\]
Так как $\chi_{ij}$ не нуль, только для ячеек, которые содержат объект, $\mathcal{L}_{coord}(i)$ ненулевая, тоже только для таких ячеек.
Квадратные корни в размерах введены, чтобы одинаковые ошибки размеров для маленьких и больших прямоугольников штрафовались по разному.
Штраф за уверенность
За уверенность будем штрафовать по разному в случае, если в ячейке есть центр объекта и если нет. Если есть, штраф считаем как:
\[\mathcal{L}_{conf}(i) = \sum_{j=1}^{B} \chi_{ij} \cdot (C_{ij} - \hat{C}_{ij})^2\]$C_{ij}$ - это уверенность, которую выдаёт сеть для $i$-ой ячейки $j$-м предсказателем, а $\hat{C}_{ij}$ - это IoU между реальным прямоугольником и тем что выдал предсказатель.
Если в ячейке нет центра объекта, то штрафуем:
\[\mathcal{L}_{noobj}(i) = (1 - \chi_i) \cdot \sum_{j=1}^{B} (C_{ij})^2\]Штрафная функция ячейки
Объединим все штрафы в одну штрафную функцию для ячейки:
\[\mathcal{L}(i) = \mathcal{L}_{class}(i) + \lambda_{coord} \cdot \mathcal{L}_{coord}(i) + \mathcal{L}_{conf}(i) + \lambda_{noobj} \cdot \mathcal{L}_{noobj}(i)\]Поскольку ячеек много, а объектов на рисунке обычно мало, то авторы выбирают $\lambda_{noobj} = 0.5$, чтобы сеть не решила, что дешевле всегда выдавать, что объектов нет. Так же ошибка на координатах обычно мала (сами координаты и размеры у нас из отрезка $[0, 1]$), поэтому авторы выбирают $\lambda_{coord} = 5$.
Результаты
Как авторы и обещали скорость работы высокая, качество при этом несколько проседает, но не кардинально. Судя по цифрам из статьи выглядит это следующим образом (тестируется на тестовой части Pascal VOC 2007):
Real-Time Detectors | Train | mAP | FPS |
------------------------------------------------
100Hz DPM | 2007 | 16.0 | 100 |
30Hz DPM | 2007 | 26.1 | 30 |
Fast YOLO | 2007+2012 | 52.7 | 155 |
YOLO | 2007+2012 | 63.4 | 45 |
------------------------------------------------
Less Than Real-Time | |
------------------------------------------------
Fastest DPM | 2007 | 30.4 | 15 |
Fast R-CNN | 2007+2012 | 70.0 | 0.5 |
Faster R-CNN VGG-16 | 2007+2012 | 73.2 | 7 |
Faster R-CNN ZF | 2007+2012 | 62.1 | 18 |
YOLO VGG-16 | 2007+2012 | 66.4 | 21 |
SSD
YOLO показал неплохие результаты: скорость выросла, а качество упало не очень сильно. Поэтому авторы статьи [7] решили продолжить и улучшить этот подход. Задача в том, чтобы повысить качество не снижая скорости.
Они предложили, так же как в YOLO, не искать объекты на фотографии, а задать фиксированный набор прямоугольников и проверять наличие объекта в каждом из них, но в YOLO претендентов было слишком мало, и к тому же особенности брались с последнего свёрточного слоя сети, а значит мелкие объекты могли в такой ситуации потеряться. Поэтому решено было брать особенности с разных свёрточных слоёв, и это автоматически привело к увеличению набора претендентов. Чтобы не заставлять сеть тренироваться так, чтобы для каждого объекта отдавать ровно одну детекцию, дополнительно после детектирования решили применить NMS (его и в YOLO применяли, и даже за счёт этого чуть улучшали качество).
Что же предлагается? Допустим у нас есть некоторая карта особенностей $m \times n$, которая получена с одного из свёрточных слоёв нейронной сети. Пройдемся по ней свёрткой с ядром $3 \times 3$, которая бы на выходе выдавала $4 + Cl$ каналов. $Cl$ - количество классов, которые мы хотим детектировать плюс “background”, а $4$ это как и в YOLO, некоторое описание прямоугольника объекта. Т.о. мы разбиваем наше изображение сеткой почти как в YOLO, потому что каждая особенность на выходе свёрточного слоя вбирает в себя информацию о пикселях квадрата в исходного изображении и значит может детектировать объект, находящийся в этом квадрате. Чем более ранний слой мы используем, чтобы забрать карту особенностей, тем больше ее размер (т.е. $m$ и $n$) и тем меньшие по размеру объекты мы сможем детектировать. Верно и обратное, раз мы детектируем объекты на карте особенностей с ядром фиксированного размера $3 \times 3$, то чтобы уметь находить большие объекты на изображении, надо брать карты особенностей с последних слоёв нейронной сети.
Замечание. В отличии от YOLO здесь мы добавляем “background” класс, т.е. делаем так же как в Faster RCNN. Соответственно, например для Pascal VOC датасета, размеченного на 20 классов у нас будет $Cl = 21$.
Чтобы детектору было легче, мы вместо одной свёртки $3 \times 3 \times (4 + Cl)$ будем добавлять несколько, и каждую такую свёртку нацелим на объекты с определенным соотношением сторон (аспектом) и масштабом. Т.е. кроме объекта у которого ограничивающий прямоугольник совпадает с набором пикселей дающих вклад в данную особенность (receiptive field) мы добавим еще объекты чуть меньше, чуть больше, вытянутые горизонтально и вытянутые вертикально. Если вспомнить FasterRCNN, то там тоже фигурировали anchor-ы, каждый из которых отвечал за позицию объекта и его соотношение сторон, но в FasterRCNN особенности брались с одного, последнего слоя сети, а здесь мы используем в том числе промежуточные слои, что должно улучшать разделяемость детектируемых объектов.
Рассмотрим картинку:
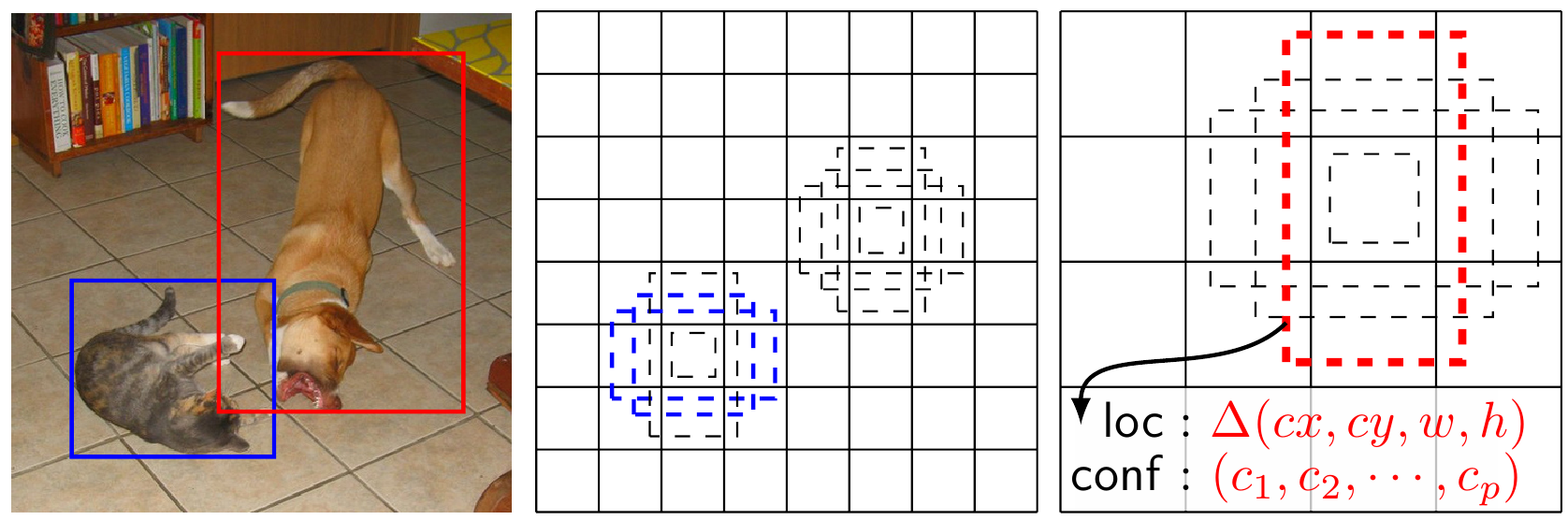
На ней два объекта: кошка и собака. Кошка достаточно небольшая, и значит детектировать её лучше всего выбирая более ранний свёрточный слой, который выдаст карту особенностей большего разрешения. А собаку наоборот, лучше детектировать взяв карту особенностей с меньшим разрешением с более позднего слоя. При этом кошка размечена таким образом, что для нее подходят несколько анкеров, а вот с собакой дело обстоит иначе с ней хорошо совпадает только один анкер.
Структура сети
Итак, возьмём сетку VGG-16, полносвязные слои представим в виде свёрточных, добавим еще немного свёрточных слоёв, и получим детектор объектов:

Для карты особенностей со слоя conv4_3 генерируем 3 анкера для каждой “точки”, а для остальных по 6. Сделано это из тех соображений, что карта особенностей со слоя conv4_3 достаточно большая ($38 \times 38$) и если использовать тот же множитель, что и для других слоёв, то это сильно замедлит работу, не добавив (или практически не добавив) качества.
Тренировка
Наше изображение покрыто плотным слоем анкеров (или default boxes в терминах статьи [7]) разных размеров и соотношения сторон.. Если в YOLO мы всегда выбирали ровно один предсказатель для каждого объекта на изображении, здесь мы собираем все default box, для которых IoU с реальным объектом больше 0.5. Поскольку в любом случае, после предсказаний сетки, мы планируем применять Non-maximum Suppression, то нет смысла тренировать сеть таким образом, чтобы она выбирала для объекта ровно один предсказатель.
Штрафная функция
Для каждого объекта, размеченного на изображении у нас может быть несколько предсказателей от которых мы готовы и хотим получить этого объекта описание. Введем как и для YOLO индикаторную функцию $\chi_{ij}$, которая равна единице, если $i$-ый анкер имеет IoU больше $0.5$ с $j$-м объектом на изображении, и ноль в случае если нет. При этом, поскольку для одного реального объекта может быть несколько анкеров имеем в виду, что вообще говоря $\sum_i \chi_{ij} \ge 1$.
Пересчитаем все анкеры, для которых нашлись реальные объекты:
\[N = \sum_{i, j} \chi_{ij}\]Штрафная функция состоит из двух слагаемых:
\[\mathcal{L} = \frac 1 N \left (\mathcal{L}_{class} + \alpha \cdot \mathcal{L}_{loc} \right)\]-
Первое слагаемое $\mathcal{L}_{class}$ отвечает за правильное определение класса объекта и суммируется по почти всем анкерам. “Почти” объясним чуть ниже.
-
Второе слагаемое - это сумма по всем анкерам, которым сопоставлен объект, т.е. $\chi_{ij} \neq 0$ и суммируются здесь штрафы за ошибки определения прямоугольника объекта. Штрафная функция считающая ошибку между двумя прямоугольниками такая же, как и штрафная функция для FastRCNN или RPN части FasterRCNN.
Поиск сложных негативов
Разберём, что значит суммирование “по почти всем анкерам” в первом слагаемом штрафной функции.
Обычно на изображении не так много объектов, которые можно задетектировать, поэтому большинство анкеров будут соответствовать негативам. Если в YOLO у нас было не слишком много ячеек (но и там мы использовали коэффициент 0.5 для штрафа за “не объект”), то здесь для стандартной SSD300 на VGG-16 мы имеем 7’308 анкеров, понятно, что подавляющее большинство из них будет негативами, если с этим перекосом не бороться, то в конечном счёте сетка решит, что дешевле метить всё как негативы.
Проблема эта известная, и решалась еще во времена бинарного классификатора, одним из подходов был поиск сложных негативов (hard negative mining). Т.е. вначале уже натренированным классификатором проверяли набор негативных примеров, находили на которых он был больше всего уверен, что это объект и пересчитывали параметры используя именно эти сложные негативы. Авторы SSD предлагают использовать такой же подход в тренировке своего детектора.
Т.е. в штрафной функции $\mathcal{L}_{class}$ мы суммируем по всем анкерам для которых нашелся позитив позитивами, и по тем анкерам негативов, для которых детектор выдал большую вероятность, что это объект. Для этого все анкеры негативов, которые детектор принял за объекты сортируются в порядке уменьшения уверености и затем для штрафной функции забираются только первые из этого набора. При этом негативов набирают такое количество, чтобы отношение негативов к позитивам не превышало 3:1.
Анкеры
На самом деле как именно выбрать default box или анкеры можно решать из соображений конкретной задачи, например, надо ли на картинке детектировать маленькие объекты (если нет то и в мелких претендентах нет смысла), вытянуты ли объекты в одном или другом направлении или они все квадратные. Однако, авторы для определенности описывают тот подход, который они применили для работы с Pascal VOC.
Допустим вы выбрали $m$ слоёв с которых будем забирать карты особенностей для детектирования объектов (в нашей схеме это conv4_3, fc7, conv6_2, conv7_2, conv8_2, conv9_2 и $m=6$) зададимся минимальным $s_{min}$ и максимальным $s_{max}$ масштабами детектируемых объектов. Мы будем искать объекты разных масштабов, используя разные карты особенностей, для минимального масштаба возьмём карту особенностей со слоя ближайшего к входу сети, затем со следующего и т.д. Если у нас выбрано $m$ слоёв, то равномерно раскидав из по масштабам получим:
\[s_k = s_{min} + \frac {s_{max} - s_{min}} {m - 1} \cdot (k - 1), k=1,...,m\]Авторы предлагают выбрать $s_{min} = 0.1$ (для conv4_3) и $s_{max} = 0.95$ (для conv9_2).
Так же для каждого масштаба, чтобы выбирать не только квадратные анкера зададимся набором аспектов $A = \{a_r | r = 1,…,T\}$, тогда размеры анкеров будут вычисляться по формулам:
\[\begin{aligned} w_k^r & = s_k \sqrt{a_r},\\ h_k^r & = \frac {s_k} {\sqrt{a_r}} \end{aligned}\]Авторы выбирают набор аспектов $A = \{1, 2, 3, \frac 1 2, \frac 1 3\}$ и для $a_r = 1$ добавляют на каждый слой анкеры с дополнительным масштабом $s’_k = \sqrt{s_k s_{k+1}}$. Таким образом, для SSD300 мы имеем по 6 анкеров для каждой особенности в карте (кроме, как было сказано выше, карты особенностей со слоя conv4_3, для которого берётся только три аспекта $\{1, \frac 1 2, 2\}$).
Позиции анкеров выбираются просто. Если мы привязываем квадраты к слою особенностей размера $m \times n$, то центры квадратов будут в точках:
\[\left(\frac {i + 0.5} {m}, \frac {j + 0.5} {n}\right), i=0, 1, ..., m;\; j=0, 1, ..., n\]Центры прямоугольников мы задаём в относительных координатах, с $(0, 0)$ в левом верхнем углу изображения и $(1, 1)$ в правом нижнем.
Расширение тренировочных данных
Чтобы модель лучше обобщилась и была устойчива. Авторы предлагают следующие варианты изменения исходной размеченной картинки при использовании ее для тренировки:
-
На вход подаётся исходная тренировочная картинка без изменений
-
Из исходной картинки вырезается кусок, таким образом, чтобы IoU объектов на картинке в вырезанном куске было 0.1, 0.3, 0.5, 0.7, 0.9.
-
Из исходной картинки вырезается случайный кусок.
Размеры вырезанного куска должны находится в пределая $[0.1, 1.0]$ исходной картинки, и соотношение сторон должно быть между $1 / 2$ до $2$. После того как кусок вырезали, с вероятностью 0.5 его зеркально отображают относительно вертикальной оси.
Дополнительные искажения на картинку не накладываются.
Результаты
Авторы тренируют две модели SSD300 - на вход подаётся картинка $300 \times 300$ и SSD500 - с входом $500 \times 500$.
Результаты на тестовой части Pascal VOC 2007:
Method | mAP | FPS |
------------------------------------
Fast R-CNN | 70.0 | 0.5 |
Faster R-CNN ZF | 62.1 | 18 |
Faster R-CNN VGG-16 | 73.2 | 7 |
YOLO | 63.4 | 45 |
Fast YOLO | 52.7 | 155 |
------------------------------------
SSD300 | 72.1 | 58 |
SSD500 | 75.1 | 23 |
-----------------------------------|
YOLO VGG-16 | 66.4 | 21 | *из предыдущей части
На MS COCO результаты SSD300 чуть похуже, авторы считают, что это из-за того, что датасет содержит много слишком мелких объектов, и их SSD локализует не достаточно точно.
| Average Precision |
Method | 0.5 | 0.75 | 0.5:0.95 |
-----------------------------------------
Fast R-CNN | 35.9 | ---- | 19.7 |
Faster R-CNN | 42.7 | ---- | 21.9 |
SSD300 | 38.0 | 20.5 | 20.8 |
SSD500 | 43.7 | 24.7 | 24.4 |
Интересная табличка в статье, про то какие именно изменения (например, включение или не включение слоя conv4_3 в генерацию претендентов, или какие аспекты добавлять для анкеров) в структуре сети и тренировке влияют на качество работы сети. Как выясняется правильное расширение данных даёт наибольший вклад.
more data augmentation? | | * | * | * | * | * |
use conv4 3? | * | | * | * | * | * |
include {1/2, 2} box? | * | * | | * | * | * |
include {1/3, 3} box? | * | * | | | * | * |
use atrous? | * | * | * | * | | * |
-------------------------------------------------------------------
VOC2007 test mAP | 65.4 | 68.1 | 69.2 | 71.2 | 71.4 | 72.1 |
YOLOv2
Следующей после SSD вышла статья [8], где авторы YOLO улучшили полноту детектора и точность позиционирования, сохранив при этом скорость работы сети.
Подробно разбирать не будем, пробежимся кратко по изменениям и улучшениям.
1 Добавили Batch Normalization. Как раз появилась оригинальная статья про батчнормализацию, и ее добавили во все сети, что совершенно логично при том насколько повышается скорость тренировки и качество результата
-
В YOLOv1 сначала тренировался классификатор на картинках $224 \times 224$, потом брались натренированные веса, добавлялись полносвязные слои, вход расширялся до $448 \times 448$ и тренировался детектор. Теперь авторы предлагают после тренировки классификатора на малом разрешении, вначале потренировать его еще 10 эпох на повышенном разрешении, и только потом уже переходить к тренировки детектора
-
Авторы заменили полносвязные слои свёрточными и перешли к схеме с анчерами. Т.е. фактически к схеме SSD. При этом у них упал $mAP$ на $0.3%$, зато полнота выросла аж на $7%$ и они решили, что $mAP$ они доберут другими способами.
-
Они “затюнили” размеры прямоугольников анкеров под датасет. Запустили k-mean кластеризацию на размерах прямоугольников объектов в тренировочном датасете и получили размеры, которые лучше для начальных предсказаний, чем как в SSD использовать просто разные соотношения сторон и масштабы.
-
Изменили штрафную функцию на позиционирование, приблизив её к варианту, который используется в SSD и FasterRCNN.
-
Вместо того, чтобы предсказывать объекты только по последнему слою особенностей, добавили в предсказателя еще и предыдущий слой. Т.е. для входного изображения $448 \times 448$ на последнем слое было $13 \times 13$ особенностей, добавили с предыдущего слоя еще $28 \times 28$. Таким образом добирая мелкие объекты.
-
Поскольку сетка, вообще говоря, не привязана к конкретному размеру изображения, то при тренировке, каждые 10 эпох меняли случайным образом размер входного изображения выбирая в пределах от $320 \times 320$ до $608 \times 608$ с шагом $32$. Фактически это похоже на тот способ расширения данных, который используется при тренировки SSD сети.
Результаты
В результате авторам удалось набрать качество не особенно замедлив работы сети:
Method | Train | mAP | FPS |
------------------------------------------------
Faster R-CNN VGG-16 | 2007+2012 | 73.2 | 7 |
Faster R-CNN ResNet | 2007+2012 | 76.4 | 5 |
YOLO | 2007+2012 | 63.4 | 45 |
YOLO VGG-16 | 2007+2012 | 66.4 | 21 |
SSD300 | 2007+2012 | 74.3 | 46 |
SSD500 | 2007+2012 | 76.8 | 19 |
------------------------------------------------
YOLOv2 288x288 | 2007+2012 | 69.0 | 91 |
YOLOv2 352x352 | 2007+2012 | 73.7 | 81 |
YOLOv2 416x416 | 2007+2012 | 76.8 | 67 |
YOLOv2 480x480 | 2007+2012 | 77.8 | 59 |
YOLOv2 544x544 | 2007+2012 | 78.6 | 40 |
------------------------------------------------
Статья [8] называется YOLO9000, но как раз про YOLO9000 я здесь писать не буду.
Заключение
Подводя итоги. Подход реализованный в YOLO, а затем улучшенный в SSD показал отличное качество при высокой скорости и может применяться наряду с подходом Faster-RCNN, особенно в случаях, когда требуется детектирование объектов в реальном времени. Можно смотреть статьи [9] и [10] на предмет улучшения и расширения. Но, в принципе, базово всё было сделано в SSD, дальше вопрос расширения данных при тренировки, возможно, улучшения процесса тренировки (например, в [9] авторы предлагают отказаться от процесса поиска сложных негативов в процессе тренировки, заменив штрафную функцию, чтобы новая меньше учитывала вклад в ошибку тех объектов, которые сеть и так уже умеет правильно классифицировать с высокой уверенностью) и прочие тонкие настройки.
Литература
-
P. Viola and M. Jones. “Robust real-time object detection”. International Journal of Computer Vision, 4:34–47, 2001.
-
P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun, “Overfeat: Integrated recognition, localization and detection using convolutional networks,” arXiv:1312.6229, 2013
-
R. Girshick, J. Donahue, T. Darrell, and J. Malik. “Rich feature hierarchies for accurate object detection and semantic segmentation.” In CVPR, 2014. arXiv:1311.2524
-
R. Girshick, “Fast R-CNN,” in IEEE International Conference on Computer Vision (ICCV), 2015.
-
S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” in Neural Information Processing Systems (NIPS), 2015.
-
J. Redmon, S. Divvala, R. Girshick, A. Farhadi, “You Only Look Once: Unified, Real-Time Object Detection”, arXiv:1506.02640, 2015
-
Wei Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, Cheng-Yang Fu, A. C. Berg, “SSD: Single Shot MultiBox Detector”, arXiv:1512.02325, 2015
-
J. Redmon, A. Farhadi, “YOLO9000: Better, Faster, Stronger”, arXiv:1612.08242, 2016
-
Tsung-Yi Lin, P. Goyal, R. Girshick, Kaiming He, P. Dollar, “Focal Loss for Dense Object Detection”, arXiv:1708.02002, 2017
-
J. Redmon, A. Farhadi, “YOLOv3: An Incremental Improvement”, arXiv:1804.02767, 2018