Графы, процесс загрубления, кластеризация
В прошлый раз разобрали некоторые общие моменты связанные с графами, теперь поговорим подробнее про разбиение графов на части, т.е. кластеризацию. Мы не будем заходить в какие-то очень тонкие детали, возможно позже разберём конкретные статьи, пока хочется получить представление о двух вещах: первая - это загрубление графа - т.е. алгоритмы уменьшающие размер графа, сохраняя его структурные свойства, вторая - это собственно кластеризация графа (в основном будем разбирать спектральную кластеризацию).
Процесс загрубления графа
Загрубление (coarsing) графа - это некий аналог масштабирования изображения (в сторону уменьшения) когда мелкие детали (высокие частоты) отбрасываются, но при этом остаётся общая картина.
В результате загрубления мы должны получить граф, вершин у которого существенно меньше чем у исходного, но при этом сохраняются те структурные свойства, которые нам необходимы. Этот подход берёт своё начало в алгоритмах решения систем линейных уравнений с сильно разреженными матрицами и с большим количеством неизвестных (например, полученных при работе с дифференциальными уравнениями через разностные схемы), а затем был использован при работе с графами, где показал свою эффективность.
Останавливаться на СЛУ мы не будем нам это в данном случае не полезно, при желании можно ознакомится с проблематикой почитав про многосеточные (multigrid) методы.
На графах процесс загрубления используется, например, при разбиение графа на части (кластеризации). Связано это с тем, что если граф содержит большое количество вершин, (а сейчас это уже скорее миллионы или десятки миллионов) применять алгоритмы разбиения к нему сложно из-за высоких затрат времени и ресурсов, поэтому вначале граф “загрубляется”, обычно последовательно несколько раз. Затем на полученном относительно небольшом графе происходит разбиение на части, после чего запускается обратный процесс, т.е. восстанавливается граф с предыдущего уровня точности, имеющееся разбиение переносится на него и, возможно, уточняется, и так до исходного графа.
Можно выделить два типа загрубления графов (см. сравнение в [1]):
-
Точное агрегирование (strict aggregation,SAG) в этом случае вершины исходного графа объединяются в одну вершину загрублённого графа, по какому-то принципу. Например, выбираются пары вершин с максимальным значением веса ребра между ними, или выбираются наборы вершин, таким образом, чтобы каждый набор был “почти кликой”. Основное, в этом типе агрегирования, что каждая вершина точного графа попадает ровно в одну вершину более грубого графа.

-
Взвешенное агрегирование (weighted aggregations, WAG) в этом случае вершина исходного графа может быть разбита на несколько частей и каждая часть попасть в свою вершину загрублённого графа.

Нам в основном интересен первый метод, поэтому вначале коротко разберём второй, а потом подробно остановимся на точном агрегировании.
Взвешенное агрегирование
Мы как всегда говорим о взвешенном графе $\mathcal G = (\mathcal V, \mathcal E)$, $\mathcal V$ - множество его вершин, а $\mathcal E$ - рёбер, с матрицей весов $W \in\mathbb R^{N\times N}$ элемент $w_{ij}$, которой задаёт вес ребра $e_{ij}$. А хотим мы построить новый взвешенный граф $\mathcal G’ = (\mathcal V’, \mathcal E’)$, вершин у которого было бы меньше чем у исходного $\vert \mathcal V’ \vert = N’ \le N = \vert \mathcal V \vert$, но при этом новый граф наследовал бы некоторые структурные свойства исходного.
Поскольку при взвешенном агрегировании одна вершина графа $\mathcal G$ может разбиться на части и принадлежать нескольким вершинам графа $\mathcal G’$, то нам надо задать матрицу перехода $P\in\mathbb R^{N\times N’}$, элемент которой $P_{i\,k’}$ будет определять какая часть вершины $i$ исходного графа попадает в вершину $k’$ загрублённого.
Получение загрубленных вершин при взвешенном агрегировании
Чтобы получить вершины графа $\mathcal G’$ выделим затравочное множество вершин $\mathcal C$ в исходном графе, и обозначим $\mathcal F = \mathcal V \setminus \mathcal C $.
Затравочное множество будем выделять следующим образом (см., например, [1]):
Положим вначале $\mathcal C = \varnothing$ и $\mathcal F = \mathcal V$. Будем переносить вершины из $\mathcal F$ в $\mathcal C$, пока вершины оставшиеся в $\mathcal F$ не будут удовлетворять неравенству:
\[\sum_{j \in \mathcal C} w_{ij} \,/\, \sum_{j\in \mathcal V} w_{ij} \ge \theta,\, i\in \mathcal F\]Т.е любая вершина из $\mathcal F$ должна быть “сильно связана” с множеством $\mathcal C$.
Теперь каждая вершина из $\mathcal C$ станет “базовой” в том смысле, что для нее будет создана отдельная вершина в новом графе $\mathcal G’$. Осталось понять как разделять на части вершины из $\mathcal F$ и какая часть будет относится к какой новой вершине в $\mathcal G’$. В [1] предлагается использовать следующий подход, наследованный от классической схемы работы многосеточных методов для систем линейных уравнений. Обозначим через $\mathcal N_i \subset \mathcal C$ множество тех вершин из $\mathcal C$, которые связаны с вершиной $i \in \mathcal F$ ребром. И обозначим $k’$ вершину в новом графе, для которой вершина $k \in \mathcal C$ исходного графа является затравочной. Определим
\[P_{i\,k'} = \begin{cases} w_{ik} / \sum_{j\in \mathcal N_i} w_{ij}, & i\in \mathcal F, k \in \mathcal N_i \\ 1, & i \in \mathcal C, k=i\\ 0, & в\,остальных\,случаях \end{cases}\]Фактически $P_{i\,k’}$ описывает вероятность, того что $i$-ая вершина исходного графа принадлежит $k’$-ой группе-вершине нового графа, и вероятность эта вычисляется на основе весов рёбер связывающих $i$-ую вершину с затравочными.
Если у исходного графа вершинам были присвоены какие-то веса или даже вектора особенностей, то несложно будет пересчитать их для вершин нового графа.
\[v'_{k'} = \sum P_{i\,k'}\cdot v_i\]Получение весов рёбер загрублённого графа при взвешенном агрегировании
Теперь нам надо определить веса рёбер нового графа. Делается это очевидным образом с использованием матрицы $P_{i\,k’}$. Для двух вершин $i$ и $j$ загрублённого графа вес ребра $w’_{ij}$ вычислим по формуле:
\[w'_{ij} = \sum_{p\neq q} P_{pi} \cdot w_{pq} \cdot P_{qj}\]т.е. вес между двумя вершинами загрублённого графа, есть сумма весов рёбер между парами вершин точного графа с учётом того, какая часть вершины точного графа попадает в новую вершину загрублённого графа.
Проекция разбиения загрублённого графа на точный при взвешенном агрегировании
Итак процесс загрубления графа при взвешенном агрегировании мы описали. Надо отметить, что в данном случае не вполне очевиден обратный процесс. Т.е. допустим мы взяли загрублённый граф и каким-то образом разрезали его на части, как теперь “пробросить” это разбиение с загрублённого графа на точный? Наиболее простой вариант выглядит следующим образом (см. [1]). Пусть мы нашли разбиение графа $\mathcal G’$, т.е. множество
\[\begin{align*} \Omega' &= \left\{\Omega'_i \subset \mathcal V', i=1,...,L \right\} \\ \mathcal V' &= \bigcup_{i=1}^L \Omega'_i,\;\Omega'_i \cap \Omega'_j = \varnothing,\, i\neq j \end{align*}\]Нам надо спроецировать это разбиение на точный граф $\mathcal G$, т.е. получить всё тоже самое только без штрихов:
\[\begin{align*} \Omega &= \left\{\Omega_i \subset \mathcal V, i=1,...,L \right\} \\ \mathcal V &= \bigcup_{i=1}^L \Omega_i,\;\Omega_i \cap \Omega_j = \varnothing,\, i\neq j \end{align*}\]Обозначим $\mathcal P_l(i)$ - вероятность, что $i$-ая вершина точного графа $\mathcal G$ принадлежит $\Omega_l$:
\[\mathcal P_l(i) = \sum_{k' \in \Omega'_l} P_{i\,k'}\]т.е. мы суммируем все части вершины $i$ точного графа, которые соответствуют вершинам из $\Omega’_l$ загрублённого графа. Теперь осталось каждую вершину точного графа определить в ту часть разбиения, вероятность которой максимальна, т.е.
\[\forall i \in \mathcal V, \, i \in \Omega_l \Leftrightarrow l = \max_{l=1,...,L} \mathcal P_l(i),\]Точное агрегирование
Перейдем к описанию процесса точного агрегирования. В данном случае каждая вершина точного графа должна попасть в какую-то вершину загрубленного графа целиком. Наиболее простой и относительно быстрый способ точного агрегирования построен на понятии паросочетания.
Паросочетания (независимые множества рёбер) графа
Паросочетание (matching) графа - это набор рёбер никакие два из которого не смежны (т.е. не имеют общую вершину). Выделяют максимальное паросочетание (maximal matching), т.е. такое паросочетание в которое нельзя добавить ещё рёбер из графа (все оставшиеся в графе рёбра смежны уже имеющимся в паросочетании). А максимальное паросочетание, которое содержит больше всего рёбер называется наибольшим паросочетанием (maximum matching). Очевидно, что не всегда максимальное паросочетание будет наибольшим, при этом наибольших паросочетаний в графе может быть несколько.
Рассмотрим, например, три паросочетания на одном и том же графе:

В первом случае максимальное паросочетание, но не наибольшее, во втором и третьем случаях два разных, но оба наибольших паросочетания.
Загрубление графа $\mathcal{G}$ с помощью точного агрегирования можно осуществить взяв некое паросочетание и склеив вершины на концах рёбер из этого набора в новые вершины. А веса новых рёбер получить просто просуммировав веса соотвествующих рёбер исходного графа. Если, например, мы склеиваем пары вершин $(i, j)$ и $(p, q)$ в $I = i\cup j$ и $P = p \cup q$, то вес ребра нового графа $w_{IP}$ будет равен сумме:
\[w_{IP} = w_{ip} + w_{iq} + w_{jp} +w_{jq}\]Поскольку обычно задача загрубления в том, чтобы максимально уменьшить количество вершин в графе (а очевидно, что при точном агрегировании мы уменьшим число вершин на каждом шаге максимум в 2 раза), то желательно выбирать максимальные и даже наибольшее паросочетания.
В [2] предлагается несколько вариантов поиска паросочетаний для загрубления графов.
Случайные паросочетания (random matching)
Можно генерировать максимальные паросочетания используя алгоритм основанный на случайном выборе. Вершины графа выбираются в случайном порядке. Если выбранная вершина $v$ еще не содержится ни в одной из пар, то случайным образом выбирается вершина $u$, которая также пока не содержится ни в одной из пар и при этом связана ребром с вершиной $v$, если удалось такую вершину $u$ выбрать, то пара $(v, u)$ добавляется в паросочетание, если вершины $u$ не нашлось (например, все связанные с $v$ вершины уже в паросочетании), то $v$ оставляется одинокой. Процесс повторяется пока не останется не осмотренных вершин. Сложность данного алгоритма очевидно пропорциональна числу рёбер исходного графа.
Такой подход позволяет получить максимальные паросочетания (но не обязательно наибольшие), а значит на каждом шаге загрубления число вершин будет существенно уменьшаться, а это именно то, что нам надо. При этом стоит отметить, что работает этот алгоритм достаточно быстро. Однако, поскольку мы не рассматриваем процесс загрубления как самоцель, а хотим последний, самый грубый граф разбить на части и потом пробросить это разбиение на исходный точный граф, то предлагается несколько усложнить алгоритм.
Паросочетания из тяжелых рёбер (heavy edge matching)
Если построить такое паросочетание, что суммарный вес рёбер из которых оно состоит максимален, то после загрубления графа с использованием этого паросочетания, суммарный вес рёбер нового графа уменьшится на максимальную величину. Действительно, если $W(\mathcal E)$ - суммарный вес рёбер исходного графа, а $W(\mathcal M)$ - суммарный вес рёбер в паросочетании, то суммарный вес рёбер загрублённого графа будет, очевидно, $W(\mathcal E’) = W(\mathcal E) - W(\mathcal M)$ (процесс получения вершин, рёбер и весов при загрублении на основе паросочетания был описан выше).
Если каждую итерацию загрубления, максимально уменьшать суммарный вес рёбер графа, то в результате получится граф у которого останутся только рёбра малого веса и при разрезании суммарный вес удалённых рёбер будет небольшим (скажем так, при прочих равных, меньше, чем если бы при загрублении мы склеивали рёбера не максимального веса). Проблема только в том, что алгоритм, который бы находил паросочетание, с максимальным суммарным весом рёбер, сам по себе будет работать слишком долго.
Поэтому предлагается (см. [2]) искать почти оптимальные в плане суммарного веса рёбер паросочетания. А для этого как и в предыдущем случае вершины обходятся случайным образом, однако, в пару к $v$ выбирается такая вершина $u$ для которой ребро $(v, u)$ имеет максимальный вес среди смежных с $v$ вершин ещё не помещённых в паросочетание.
Скорость работы такого алгоритма, также как и предыдушего, пропорциональна числу рёбер исходного графа. Не смотря на то, что мы и находим возможно не самое оптимальное (с точки зрения максимального суммарного веса) паросочетание, качество дальнейшей кластеризации при так построеном процессе загрубления остаётся на хорошем уровне (во всяком случае, так пишут авторы [2] ссылаясь на проведённые эксперименты).
Интересно, что работает и обратный подход, когда вместо паросочетаний из тяжёлых рёбер выбираются паросочетания из лёгких рёбер (light edge matching). В результате вершины загрублённого графа будут иметь большую степень, а это полезно для некоторых алгоритмов разбиения графа.
Паросочетания на тяжелых кликах (heavy click matching)
Кликой неориентированного графа называется подмножество его вершин, любые две из которых соединены ребром. Логично при загрублении в одну вершину нового графа объединять вершины составляющие клику или почти клику. Если мы возьмём граф $\mathcal G = (\mathcal V, \mathcal E)$ и выберем из него подграф на множестве вершин $U \subset \mathcal V$, рёбра которого образуют множество ${\mathcal E}_U$ (в ${\mathcal E}_U$ включаются только те рёбра исходного графа, вершины на концах которых находятся в $U$). Соотношение:
\[\mu(U) = \frac {2\vert {\mathcal E}_U \vert} {\vert U \vert \left(\vert U \vert - 1\right)}\]можно считать мерой того насколько $U$ есть клика. Действительно, если $U$ - клика, то $\mu(U) = 1$, и чем менее связан набор вершин $U$ тем ближе метрика к нулю.
Рассматриваемый алгоритм загрубления графа (взят снова из [2]) соединяет в новые вершины множество вершин исходного графа образующих клики или “почти клики”, т.е. метрика $\mu(U)$ которых достаточно близка к единице. Работа алгоритма, однако, похожа на предыдущие два. Во-первых, на каждом шаге загрубления ищется паросочетание, во-вторых, при поиске вершины обходятся случайным образом.
Определим метрику плотности ребра между вершинами $u$ и $v$:
\[\mu(u, v) = \frac {2\left(c_e(u) + c_e(v) + c_e(u, v)\right)} {\left(c_v(u) + c_v(v)\right)\left(c_v(u) + c_v(v) - 1\right)}\]здесь $u$ и $v$ вершины (возможно уже загрублённого графа, т.е. мы мы уже сделали несколько итераций загрубления исходного графа). $c_v(u)$ - количество вершин исходного графа схлопнутых внутрь вершины $u$ на предыдущих этапах загрубления графа, аналогично, $c_e(u)$ - количество рёбер исходного графа схлопнутых внутрь вершины $u$ на предыдущих этапах загрубления. И, наконец, $c_e(u, v)$ - количество рёбер исходного графа схлопнутых внутрь ребра между вершинами $u$ и $v$.
На каждом этапе загрубления вершины графа выбираются в случайном порядке. Для выбранной вершины $v$ проверяются все смежные еще не определенные в паросочетание вершины и выбирается та, которая даёт максимальное значение плотности ребра.
В [2] речь идёт именно о количестве рёбер внутри грубой вершины и внутри грубого ребра, но ничто не мешает вместо количества рёбер использовать сумму весов рёбер (практически количество это суммарный вес, когда у всех рёбер вес равен единице).
На этом с загрублением закончили, переходим к кластеризации.
Разбиение графов на части (кластеризация)
Кластеризация - это разбиение множества вершин $\mathcal V$ графа $\mathcal G$ на непересекающиеся наборы:
\[\mathcal V = \bigcup_{i = 1}^L \mathcal V_i,\, \mathcal V_i \cap \mathcal V_j = \varnothing,\, i\ne j\]Важный вопрос, а что считать хорошим разбиением? И как определять, имея два разбиения, какое из них лучше? Очевидно, что с одной стороны это зависит от предметной области задачи, с другой, если мы свели нашу задачу к графу, то хотелось бы иметь общие подходы в рамках графовой модели.
Начнём с простого случая $L = 2$, т.е. будем разбивать граф на две части. Разбиение вершин графа на две непересекающиеся части принято называть разрез графа. Разрез графа $\mathcal G = (\mathcal V, \mathcal E)$ - это такие множества $\mathcal A$ и $\mathcal B$
\[\mathcal V = \mathcal A \cup \mathcal B, \, \mathcal A \cap \mathcal B = \varnothing\]Можно ввести понятие величина разреза или вес разреза - сумма весов рёбер графа, которые соединяют вершины, находящиеся в разных частях разреза.
\[cut(\mathcal A, \mathcal B) = \sum_{i \in \mathcal A, j\in \mathcal B} w_{ij}\]Величину разреза саму по себе можно сделать критерием качества разбиения: чем меньше величина разреза, тем лучше разбиение. Действительно, логично, что разваливать граф на две части надо так, чтобы пришлось выбросить (разрезать) минимальное по суммарному весу число рёбер. Очевидно, если вес у всех рёбер одинаковый, то минимальная величина разреза превратится в минимальное количество выбрасываемых рёбер. Однако, в [4] авторы предлагают следующую модель, на которой такой критерий не работает:
Т.е. минимальная величина разреза не всегда критерий “хорошести” разреза. Но и отбрасывать его сразу не стоит, например, если мы в задаче сразу фиксируем необходимость разбивать вершины на два равных (или почти равных) множества, то и оптимизация просто величины разреза вполне подходящий критерий. Рассмотрим, например, описанный в [3] алгоритм разбиения графа на два равных подграфа.
Алгоритм Kernighan–Lin (KL)
KL алгоритм описан в [3] и изначально предполагается к использованию, для разбиения графа с четным числом вершин на две равные части таким образом, чтобы величина разреза была минимальна. Однако, его можно обобщить и на вариант разбиения графа более чем на две части, а так же и на неравные части (см. там же в [3]).
Работает этот алгоритм итерационно. Вначале множество вершин разбивается произвольным образом на две равные части
\[\mathcal V = \mathcal A \cup \mathcal B, \, \vert \mathcal A \vert = \vert \mathcal B \vert, \, \mathcal A \cap \mathcal B = \varnothing\]А затем выбираем пару вершин: одну из $\mathcal A$ и вторую из $\mathcal B$ и пытаемся поменять их местами (т.е. первую отправить в множество $\mathcal B$, а вторую в множество $\mathcal A$) и оценить уменьшиться ли при этом величина разреза. Изменение величины разреза определяет следующее утверждение:
Для вершины $a \in \mathcal A$ определим величину
\[D(a) = \sum_{v\in \mathcal B} w_{a\,v} - \sum_{v\in \mathcal A} w_{a\,v},\]аналогично, для любой вершины $b \in \mathcal B$ положим
\[D(b) = \sum_{v\in \mathcal A} w_{b\,v} - \sum_{v\in \mathcal B} w_{b\,v}.\]Тогда если мы переместим вершину $a$ в множество $\mathcal B$, а вершину $b$ наоборот в множество $\mathcal A$, то величина разреза уменьшится на
\[G(a,b) = D(a) + D(b) - 2w_{ab}.\]Теперь, взяв начальное разбиение, можно выбрать пару вершин с максимальным $G(a, b)$ и поменять их местами, затем следующую пару и т.д., пока не придем к ситуации минимальной величины разреза. Правда минимум будет только локальным. Поэтому затем предлагается взять другое начальное разбиение и повторить процедуру, таким образом получить новый локальный минимум возможно меньше предыдущего. Повторяя процедуру несколько раз с разным начальным разбиением, можно выбрать результат в котором получился минимальный вес разреза.Ы
В качестве полезной эвристики авторы статьи [3] предлагают вначале применить процедуру разбиения на каждом из начальных множеств получив таким образом $\mathcal A = \mathcal A_1 \cup \mathcal A_2$ и $\mathcal B = \mathcal B_1 \cup \mathcal B_2$, а затем взять в качестве начального разбиения: $\mathcal A_0 = \mathcal A_1 \cup \mathcal B_1$ и $\mathcal B_0 = \mathcal A_2 \cup \mathcal B_2$.
Критерии кластеризации
Вернёмся к критериям качества кластеризации и попробуем собрать некоторые известные варианты.
Для начала определим функцию:
\[links(\mathcal A, \mathcal B) = \sum_{i \in \mathcal A, j\in \mathcal B} w_{ij},\, \forall \mathcal A \subset \mathcal V,\,\mathcal B \subset \mathcal V\]фактически это тоже самое, что и $cut()$ только без привязки к разрезу или разбиению графа, на самом деле, ничто не мешает нам, например, вычислить функцию $links(\mathcal A, \mathcal A)$ - это будет просто сумма весов всех внутренних рёбер множества вершин $\mathcal A$. Более того можно по аналогии со степенью вершины, ввести понятие степень набора вершин и определить её как:
\[degree(\mathcal A) \equiv links(\mathcal A, \mathcal V)\]Несложно заметить, что
\[degree(\mathcal A) \equiv links(\mathcal A, \mathcal V) = links(\mathcal A, \mathcal A) + links(\mathcal A, \mathcal V \setminus \mathcal A)\]Величина разреза
Мы уже достаточно подробно про этот критерий поговорили. Функция которую надо оптимизировать:
\[links(\mathcal A, \mathcal B) \rightarrow \min\]Не сложно обобщить этот критерий и на случай разбиения при $L > 2$:
\[\sum_{l=1}^L links(\mathcal V_l, \mathcal V \setminus \mathcal V_l) \rightarrow \min\]Важно еще раз отметить, что сам по себе критерий не всегда хорош, а в KL мы всё таки оптимизируем функцию с учётом существенного условия $\vert\mathcal A \vert = \vert \mathcal B \vert$.
Относительная величина разреза (ratio cut)
В [6] авторы предложили использовать в качестве целевой функции относительную величину разреза:
\[RCut = \sum_{l=1}^L \frac {links(\mathcal V_l, \mathcal V \setminus \mathcal V_l)} {\vert \mathcal V_l \vert} \rightarrow \min\]Действительно, интуитивно это выглядит как хороший вариант разбиения, с одной стороны за счёт величин в числителях мы уменьшаем вес выбрасываемых рёбер, с другой, за счёт знаменателей не даём выбирать слишком маленькие наборы вершин, и пытаемся заставить разбивать на относительно одинаковые по мощности множества.
Средняя или относительная близость (average/ratio association)
Другой вариант целевой функции был предложен в [7]:
\[RAssoc = \sum_{l=1}^L \frac {links(\mathcal V_l, \mathcal V_l)} {\vert \mathcal V_l \vert} \rightarrow \max\]Т.е. вместо того, чтобы уменьшать вес выброшенных рёбер, мы пытаемся строить разрез таким образом, чтобы увеличить относительный вес рёбер внутри кластеров.
Нормализованная величина разреза/близость (normalized cut/association)
Там же в [7] авторы предлагаю еще один вариант целевой функции, у которой в знаменателях стоит не количество вершин, а суммарный вес рёбер:
\[NCut = \sum_{l=1}^L \frac {links(\mathcal V_l, \mathcal V \setminus \mathcal V_l)} {degree\left( \mathcal V_l \right) } \rightarrow \min\]учитывая, что $links(\mathcal V_l, \mathcal V \setminus \mathcal V_l) = degree\left( \mathcal V_l \right) - links(\mathcal V_l, \mathcal V_l)$, можно эту задачи оптимизации заменить эквивалентной:
\[NAssoc = \sum_{l=1}^L \frac {links(\mathcal V_l, \mathcal V_l)} {degree\left( \mathcal V_l \right) } \rightarrow \max\]Обобщённая взвешенная близость/величина разреза (general weighted cut/association)
Наконец, в [5] предлагают обобщить подход, введя для каждой вершины $i$ вес $s_i$, тогда, обозначив $S\left(\mathcal V_l\right) = \sum_{i\in\mathcal V_l}s_i$, можно обобщить вариант с разрезами на:
\[WCut = \sum_{l=1}^L \frac {links(\mathcal V_l, \mathcal V \setminus \mathcal V_l)} {S\left( \mathcal V_l \right) } \rightarrow \min\]а вариант с близостью вершин на:
\[NAssoc = \sum_{l=1}^L \frac {links(\mathcal V_l, \mathcal V_l)} {S\left( \mathcal V_l \right) } \rightarrow \max\]Варианты относительной близости и относительной величины разреза получаются из обобщённого, если положить вес каждой вершины равным единице. А нормализованные варианты получаются, если вес вершины приравнять к её степени (сумме весов выходящих из нее рёбер).
Спектральная кластеризация
Как для графа вводится лапласиан в разных его вариациях, мы уже обсудили. На базе этого оператора, мы так же отыскали собственные числа и собственные вектора, и таким образом ввели понятие спектра графа. Так же было отмечено, что собственные вектора лапласиана тесно связаны с вопросами кластеризации графа.
Как мы отмечали раньше у лапласиана всегда есть собственное число $\lambda = 0$ при этом, если граф несвязный, т.е. состоит из нескольких компонент, то порядок этого собственного числа равен числу компонент связности графа, а каждый из собственных векторов, соответствующих $\lambda = 0$, определяет вершины одной компоненты связности (фактически каждый собственный вектор определяет характеристическую функцию одной из компонент связности).
Понятно, что кластеризацию мы планируем применять на связном графе. А значит, $\lambda = 0$ собственное число первой степени лапласиана этого графа и координаты соответствующего собственного вектора все равны ненулевой константе (значение константы зависит от нормализации). Это малополезно в нашей задаче, но наводит на мысль, что собственные вектора графа могут помочь в его кластеризации. Действительно, присмотримся ко второму собственному вектору (мы нумеруем вектора в порядке возрастания соответствующих собственных чисел). В работе [9] показывается, что для связного графа, если взять второй собственный вектор $\xi^{(2)} = \left(\xi^{(2)}_1, …, \xi^{(2)}_n\right)$ лапласиана (в [9] используется ненормализованный лапласиан), и задаться некоторым произвольным действительным числом $T \in \mathbb R$, то разрез исходного графа:
\[\begin{align*} \mathcal A &= \left\{i \in \mathcal V \,\vert\, \xi_i < T \right\}\\ \mathcal B &= \left\{i \in \mathcal V \,\vert\, \xi_i \ge T \right\} \end{align*}\]будет таким, что и $\mathcal A$ и $\mathcal B$ будут связными. Это крайне важный момент, получается, что сдвигая пороговое значение $T$ мы будем получать разные разбиения графа на связные части. Интуитивно понятно, что в разные множества попадут “более связные” части графа.
Мы уже рассматривали граф:

и строили для него графики координат собственных векторов:
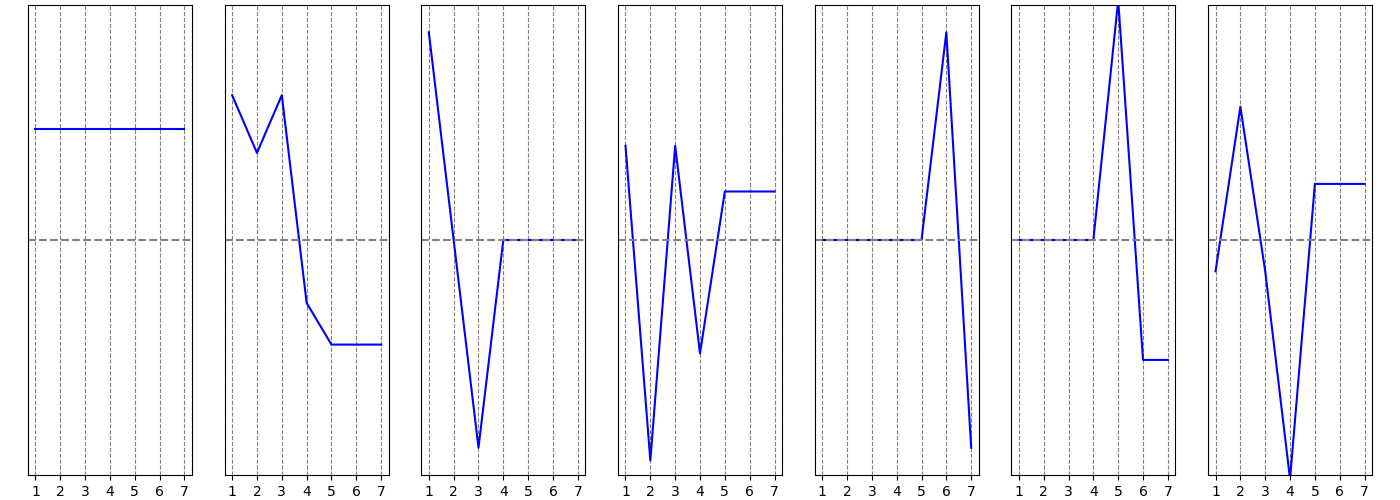
Видно, что в данном случае порог $T = 0$ даст нам интуитивно хороший разрез графа. Так же следует отметить, что какое бы пороговое значение мы не взяли вершины $1$ и $3$ всегда будут в одной компоненте, и, аналогично, всегда в одну компоненту попадут вершины $5$, $6$ и $7$. И это кажется вполне логичным.
Таким образом, если мы хотим разбить граф на две равные “хорошо связные” части то можно взять координаты второго собственного вектора лапласиана, отсортировать их и применить несколько очевидных способов.
-
найти медиану и вершины соответствующие координатам меньше медианы поместить в одно множество, остальные в другое.
-
найти максимальный разрыв в отсортированном множестве и разделить вершины по порогу из этого разрыва
-
выбрать порог используя, например, метод k-средних (k-mean) для $k =2$.
-
взять вершины, соответствующие положительным координатам, в один набор, а остальные в другой.
Надо отметить, что любой вариант с выбором некоего порога по которому разделять вершины, не гарантирует разделения на два равных по мощности множества потому что часть вершин может иметь одно и тоже значение координат собственного вектора и разделить их по порогу просто не получится.
Самое главное пока не очевидно удовлетворяет ли такой разрез хоть каким-то критериям оптимизации из тех, что мы сформулировали ранее.
Минимизация RCut
В [8] предлагается следующее рассуждение (на самом деле исходная статья [7], но в [8] рассуждения на мой взгляд понятнее), которое показывает связь координат второго собственного вектора лапласиана графа с разрезом минимизирующим $RCut$. Определим вектор $f = \left(f_1, f_2, …, f_N\right)^T \in \mathbb R^N$ следующим образом:
\[f_i = \begin{cases} \sqrt{\frac {\vert \mathcal B \vert} {\vert \mathcal A \vert}}, \, i \in \mathcal A\\ -\sqrt{\frac {\vert \mathcal A \vert} {\vert \mathcal B \vert}}, \, i \in \mathcal B\\ \end{cases}\]теперь, используя симметричный ненормализованный лапласиан графа можем записать:
\[\begin{align*} f^T \mathcal L f &= \frac 1 2 \sum_{i,j=1}^N w_{ij}\left(f_i - f_j\right)^2 =\\ &= \frac 1 2 \sum_{i\in\mathcal A,j\in\mathcal B} w_{ij}\left(\sqrt{\frac {\vert \mathcal B \vert} {\vert \mathcal A \vert}} + \sqrt{\frac {\vert \mathcal A \vert} {\vert \mathcal B \vert}}\right)^2 + \frac 1 2 \sum_{i\in\mathcal B,j\in\mathcal A} w_{ij}\left(-\sqrt{\frac {\vert \mathcal B \vert} {\vert \mathcal A \vert}} - \sqrt{\frac {\vert \mathcal A \vert} {\vert \mathcal B \vert}}\right)^2 =\\ &= \frac 1 2 \left(\sqrt{\frac {\vert \mathcal B \vert} {\vert \mathcal A \vert}} +\sqrt{\frac {\vert \mathcal A \vert} {\vert \mathcal B \vert}}\right)^2 links(\mathcal A, \mathcal B) + \frac 1 2 \left(\sqrt{\frac {\vert \mathcal B \vert} {\vert \mathcal A \vert}} +\sqrt{\frac {\vert \mathcal A \vert} {\vert \mathcal B \vert}}\right)^2 links(\mathcal B, \mathcal A) =\\ &= links(\mathcal A, \mathcal B) \left(\frac {\vert \mathcal B \vert} {\vert \mathcal A \vert} + \frac {\vert \mathcal A \vert} {\vert \mathcal B \vert} +2\right) =\\ &= links(\mathcal A, \mathcal B) \left(\frac {\vert \mathcal B \vert + \vert \mathcal A \vert} {\vert \mathcal A \vert} + \frac {\vert \mathcal A \vert + \vert \mathcal B \vert} {\vert \mathcal B \vert}\right) =\\ &= \vert \mathcal V \vert \cdot \left(\frac {links(\mathcal A, \mathcal B)} {\vert \mathcal A \vert} + \frac {links(\mathcal A, \mathcal B)} {\vert \mathcal B \vert}\right)=\\ &= \vert \mathcal V \vert \cdot RCut(\mathcal A, \mathcal B) \end{align*}\]иначе говоря:
\[RCut(\mathcal A, \mathcal B) = \frac 1 {\vert \mathcal V \vert} f^T \mathcal L f\]далее
\[\left(1, 1, ..., 1\right) \cdot f = \sum_{i=1}^N f_i = \sum_{i\in\mathcal A} \sqrt{\frac {\vert \mathcal B \vert} {\vert \mathcal A \vert}} - \sum_{i\in\mathcal B} \sqrt{\frac {\vert \mathcal A \vert} {\vert \mathcal B \vert}} = \vert \mathcal A\vert \sqrt{\frac {\vert \mathcal B \vert} {\vert \mathcal A \vert}} - \vert \mathcal B\vert \sqrt{\frac {\vert \mathcal A \vert} {\vert \mathcal B \vert}} = 0\]значит вектор $f$ ортогонален вектору из единиц, т.е. первому собственному вектору лапласиана.
Наконец,
\[\left \| f \right \|^2 = \sum_{i=1}^N f_i^2 = \vert \mathcal A \vert \frac {\vert \mathcal B \vert} {\vert \mathcal A \vert} + \vert \mathcal B \vert \frac {\vert \mathcal A \vert} {\vert \mathcal B \vert} = \vert \mathcal A \vert + \vert \mathcal B \vert = N\]Таким образом, задача
\[RCut(\mathcal A, \mathcal B) \rightarrow \min\]эквивалентна
\[f^T \mathcal L f \rightarrow \min,\, f \perp \mathbb{1},\, \left \| f \right \| = \sqrt{N}\]и координаты $f$ принимают только два возможных значения, заданных формулой выше.
К сожалению, в таком виде (когда координаты вектора принимают ровно два возможных значения) задача будет NP-сложной. Однако, если условие только двух возможных значений координат отбросить, то
\[g^T \mathcal L g \rightarrow \min,\, g \perp \mathbb{1},\, \left \| g \right \| = \sqrt{N}\]даёт в качестве решения $g$ как раз собственный вектор, соответствующий второму по величине собственному значению матрицы лапласиана (см., например, [10]). Таким образом связь показана, правда мы решили не совсем задачу минимизации $RCut$, т.к. координаты вектора $g$ у нас произвольны. Мы можем применить один из способов описанных ранее (вершины соответствующие положительным координатам вектора $g$ в одно множество, отрицательным - в другое, или как-то еще), чтобы разделить вершины на основе координат вектора $g$. Чаще всего координаты разделяются на две части с использованием алгоритма k-средних. Но чёткой гарантии оптимальности $RCut$ у нас всё-таки нет.
Итак для простого разреза графа на две части, связь задачи минимизации со втором собственным вектором симметричного ненормализованного лапласиана, будем считать установленой. Перейдём к варианту разреза на $L > 2$ частей.
Для каждой части $\mathcal V_l, l=1,…,N$ определим характеристический вектор $h_l = \left(h_{1,l}, f_{2,l}, …, f_{N,l}\right)^T \in \mathbb R^N$:
\[h_{i,l} = \begin{cases} \frac 1 {\sqrt{\vert \mathcal V_l \vert}}, \, i \in \mathcal V_l\\ 0, \, i \notin \mathcal V_l \end{cases}\]из этих векторов соберём матрицу $H \in \mathbb R^{N\times L}$ (вектора - столбцы матрицы). В силу того, как определены вектора $h_l$ имеем $H^TH=I$. Теперь, проделав преобразования аналогичные тем, что проделаны для случая двух множеств можно показать, что
\[h_l^T \mathcal L h_l = \frac {links(\mathcal V_l, \mathcal V \setminus \mathcal V_l)} {\vert \mathcal V_l \vert}\]так же не трудно видеть, что
\[h_l^T \mathcal L h_l = \left(H^T \mathcal L H\right)_{l\,l}.\]Теперь выразим $RCut$, через матрицу $H$:
\[RCut\left(\mathcal V_1, ..., \mathcal V_L\right) = \sum_{l=1}^N h_l^T \mathcal L h_l = \sum_{l=1}^N \left( H^T \mathcal L H\right)_{l\,l} = {\rm trace} \left( H^T \mathcal L H\right)\]Аналогично случаю разбиения на две части, здесь также можем заменить задачу оптимизации $RCut$ на эквивалентную:
\[{\rm trace} \left( H^T \mathcal L H\right) \rightarrow \min,\, H^TH=I\]с учётом того, что элементы матрицы $H$ определены выше.
Так же как в случае двух частей, мы ослабляем условие, заменяя эту задачу на более простую, убирая ограничения на значения матрицы $H$:
\[{\rm trace} \left( B^T \mathcal L B\right) \rightarrow \min,\, B^TB=I,\, B\in\mathbb R^{N\times L}\]а данная задача имеет известное решение - матрицу $B$ составленную из первых $L$ собственных векторов (столбцов) лапласиана. Чтобы вернуться к матрице $H$ нам снова нужны дополнительные усилия. В данном случае опять можно использовать алгоритм k-средних. Применим его к $N$ строкам матрицы $B$, как векторам в пространстве размерности $L$. Каждой строке соответствует вершина в исходном графе, таким образом, разбив на $L$ множеств вектора-строки из $B$ мы получим разбиение на $L$ множеств вершин графа.
Минимизация NCut
Случай когда в качестве критерия разбиения выбирается метрика $NCut$ решается очень похоже. Для разбиения на два множества, выберем вектор:
\[f_i = \begin{cases} \sqrt{\frac {degree\left( \mathcal B \right)} {degree\left( \mathcal A \right)}}, \, i \in \mathcal A\\ -\sqrt{\frac {degree\left( \mathcal A \right)} {degree\left( \mathcal B \right)}}, \, i \in \mathcal B\\ \end{cases}\]Так же как и ранее, можно показать, что $(Df)^T\mathbb{1} = 0$, $f^TDf=degree(V)$ и $f^TLf = degree(V)NCut(\mathcal A, \mathcal B)$, а значит, можно проблему минимизации $NCut$ заменить на эквивалентную:
\[f^T \mathcal L f \rightarrow \min,\, Df \perp \mathbb{1},\, f^T D f = degree(\mathcal V)\]Координаты $f$ принимают два возможных значения. Ослабляя условия задачи переходим к произвольному вектору $g$:
\[g^T \mathcal L g \rightarrow \min,\, Dg \perp \mathbb{1},\, g^T D g = degree(\mathcal V)\]делаем подстановку $\hat g = D^{1/2}g$ ($D$ у нас диагональная матрица):
\[{\hat g}^T D^{-1/2} \mathcal L D^{-1/2}{\hat g} \rightarrow \min,\, \hat g \perp D^{1/2}\mathbb{1},\, \left \| \hat g\right \|^2 = degree(\mathcal V)\]очевидно, что здесь симметричный ненормализованный лапласиан можно заменить на нормализованный симметричный: $\mathcal L_{sym} = D^{-1/2} \mathcal L D^{-1/2}$, у которого $D^{1/2}\mathbb{1}$ есть первый собственный вектор. А значит решением задачи будет второй собственный вектор $\mathcal L_{sym}$, возвращаясь к вектору $g = D^{-1/2}{\hat g}$ можно сделать вывод, что вектор $g$ это второй собственный вектор нормализованного несимметричного лапласиана $\mathcal L_{rw}$ или в других обозначениях обобщенный собственный вектор $\mathcal L u = \lambda D u$.
Для случая $L > 2$ матрица $H$ задаётся как:
\[h_{i,l} = \begin{cases} \frac 1 {\sqrt{degree(\mathcal V_l)}}, \, i \in \mathcal V_l\\ 0, \, i \notin \mathcal V_l \end{cases}\]и в качестве результата получаем $L$ первых собственных вектором несимметричного нормализованного лапласиана $\mathcal L_{rw}$, используя которые и метод k-средних находим разбиение графа.
Алгоритм спектральной кластеризации
Итак резюмируя мы можем строить алгоритм спектральной кластеризации графа следующим образом.
-
Находим $L$ первых собственных векторов лапласиана (симметричного ненормализованного или несимметричного нормализованного).
-
Строим из этих собственных векторов матрицу используя их в качестве столбцов.
-
Рассматриваем строки матрицы как новый набор из $N$ векторов размерности $L$, каждый из которых соответствует вершине графа.
-
Применяем алгоритм кластеризации на этих векторах (например, алгоритм k-средних)
-
Переносим кластеризацию векторов на кластеризацию, соответствующих этим векторам, вершины графа.
Проблемы спектральной кластеризации
Основная проблема описанного алгоритма заключается в том, что решать задачу напрямую мы не можем, а ослабляя условия мы решаем всё-таки не совсем ту задачу оптимизации, которую сформулировали. Поэтому хотя “чаще всего в практических задачах” алгоритм описанный выше “работает достаточно хорошо”, возможны и плохие случаи. Например, в [11] рассматривается вот такой граф:

Оптимальный разрез с точки зрения $RCut$ на две части, очевидно, должен отбросить рёбра $(k, k+1)$ и $(3k, 3k+1)$ и получить два набора $\mathcal A = \{1, 2, …, k, 2k+1, …, 3k\}$ и $\mathcal B = \{k+1, k+2, …, 2k, 3k+1, …, 4k\}$. Однако, авторы [11] показывают, что спектральная кластеризация на базе второго собственного вектора приводит к выкидыванию всех вертикальных рёбер $(k + i, 3k + i),\, i=1,…,k-1$ и разбиению вершин на два множества: $\tilde {\mathcal A} = \{1, 2, …, 2k\}$ и $\tilde {\mathcal B} = \{2k+1, k+2, …, 4k\}$, т.е. вариант спектральной кластеризации выдаёт $RCut$ в $k/2$ раз хуже чем оптимальный. Понятно, что произойдёт, если увеличивать $k$.
Но всё же во многих практических задачах спектральная кластеризация показывает очень хорошие результаты.
Мы пока не обсуждаем поиск собственных векторов матрицы и численные методы связанные с этой задачей. Одним из известных и широко применяемых является метод Ланцоша (Lanczos).
Литература
-
C. Chevalier, I. Safro. “Comparison of Coarsening Schemes for Multilevel Graph Partitioning”, 2009
-
G. Karypis, V. Kumar. “A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs”, 1998
-
B. W. Kernighan, S. Lin. “An efficient heuristic procedure for partitioning graphs”, 1969
-
Cheng, Chung-Kuan, Y. Wei. “An improved two-way partitioning algorithm with stable performance [VLSI].”, 1991
-
I. S. Dhillon, Y. Guan, B. Kulis, “Weighted Graph Cuts without Eigenvectors A Multilevel Approach”, 2007
-
L. Hagen, A. Kahng, “New spectral methods for ratio cut partitioning and clustering”, 1992
-
J. Shi, J. Malik, “Normalized Cuts and Image Segmentation”, 2000
-
Ulrike von Luxburg. “A Tutorial on Spectral Clustering”, arXiv:0711.0189, 2007
-
M. Fiedler. “Algebraic connectivity of graphs”, 1973
-
Р. Беллман. “Введение в теорию матриц”, 1969
-
S. Guattery, G. Miller. “On the quality of spectral separators”, 1998