Нейронная сеть с вейвлет преобразованием для удаления дождя.
Недавно смотрел на статью про детектирование объектов в дождь и вывод был такой, что надо не убирать дождь с фотографий на которых планируем детектировать, а собирать и размечать датасет с фотографиями в дождь (или как-то еще работать на этапе тренировки). Но тут наткнулся на статью про то как убирать дождь с фотографий с использованием нейронных сетей и вейвлет преобразований, и понятно не смог устоять ибо вейвлет преобразования - это прекрасно и к тому же ностальгия.

Вейвлет преобразования
Для одномерного сигнала взятого в точках отсчета количеством T штук, вайвлет преобразование с базисом Хаара выдаёт два набора длины T/2, первый набор содержит в элементе с индексом i среднее арифметическое (полусумму) элементов с индексами 2*i и 2*i + 1 исходного сигнала, а второй - полуразность. Отсюда следует, в том числе, что такое вейвлет преобразование не теряет информации, и обратным преобразованием можно восстановить сигнал. При этом первый набор получается как результат низкочастотной фильтрации (Low pass filter), а второй - высокочастотной (High pass filter).
Для двумерного сигнала (например, картинки) всё примерно тоже самое, только фильтр применяется вначале по строке, потом по столбцу (или наоборот, смысл не меняется). И соответственно, из матрицы W x H получаем четыре матрицы W/2 x H/2, результаты работы фильтров LL, HL, LH, HH. Причем результат LL фильтра это просто исходная картинка масштабированная с коэффициентом 1/2, HL и LH подсветят вертикальные и горизонтальные рёбра, а HH - что вроде диагональных рёбер.
Вейвлет преобразование (DWT) с базисом Хаара хорошо ложится на свёрточные нейронные слои. Действительно, это преобразование можно представить в виде четырёх свёрточных слоёв с ядром 2 x 2 и шагом равным 2. Аналогично, обратное вейвлет преобразование (IDWT) можно представить в виде deconvolution слоя. Веса этих слоёв, фиксированы и не тренируются, нелинейность - отсутствует.
Удаление дождя
Авторы предлагают, удалять дождь с фотографий, используя свёртки и вейвлет преобразования. Сама нейронная сеть, для очистки картинки выглядит стандартно: энкодер + декодер + UNet пробрасывание features:
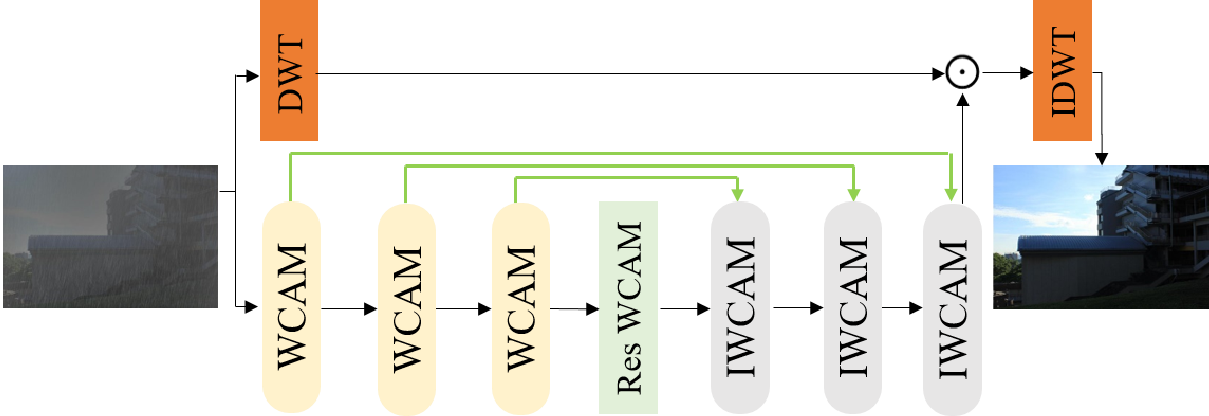
На выходе декодера правда не сразу очищенная картинка, а четыре карты весов. Чтобы получить результат, надо применить к “дождливой” картинке вейвлет преобразование, очистить каждую из частей (LL, HL, LH, HH), используя соответствующую карту весов и восстановить фотографию при помощи обратного вейвлет преобразования.
Основное отличие от стандартных CNN сетей заключается в использовании специальных слоёв WCAM (wavelet channel attention module) и IWCAM (inverse wavelet channel attention module).
WCAM
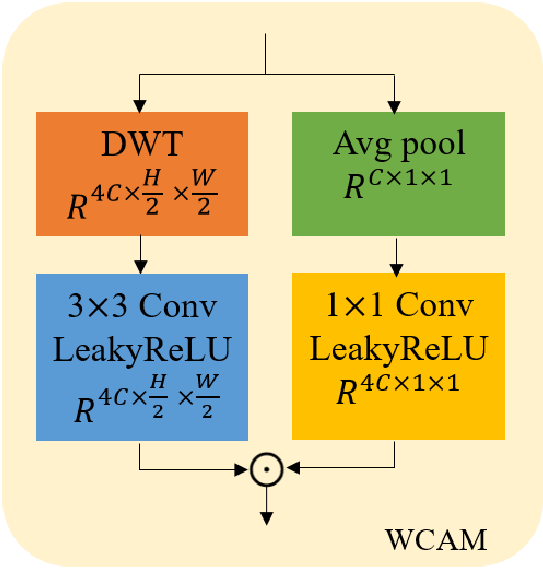
WCAM слой используется в энкодере. Входной тензор размера W x H x C запускается по двум веткам:
-
Применяется вейвлет преобразование, при этом ширина и высота уменьшается вдвое, а число каналов увеличивается в 4 раза, т.е. получается тензор размера W/2 x H/2 x 4C. Затем результат подаётся на обычный свёрточный слой с ядром 3 x 3 и LeakyReLU в качестве нелинейности.
-
Применяется global average pooling, т.е. тензор усредняется в размер 1 x 1 x C. Затем этот столбик при помощи свёрточного слоя с ядром 1 x 1 удлиняется в 4 раза, т.о. на выходе имеем 1 x 1 x 4C
Наконец, результаты обеих веток объединяются: каждый канал выходного тензора из первой ветки умножается на соответствующий вес, полученный от второй ветки. Т.е. происходит дополнительное перевезвешивание каналов features. Этот подход авторы почерпнули из статьи Jie Hu et al. “Squeeze-and-excitation networks”.
IWCAM
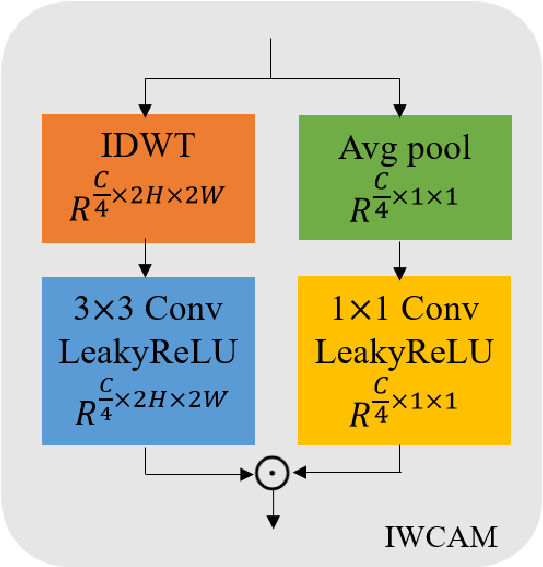
IWCAM - слой симметричный WCAM, но только в декодере. Всё аналогично WCAM тоже две ветки, только вместо прямого вейвлет преобазования - обратное и, соответственно, входной тензор размера W x H x C на выходе превращается в тензор размера 2W x 2H x C/4.
Res WCAM
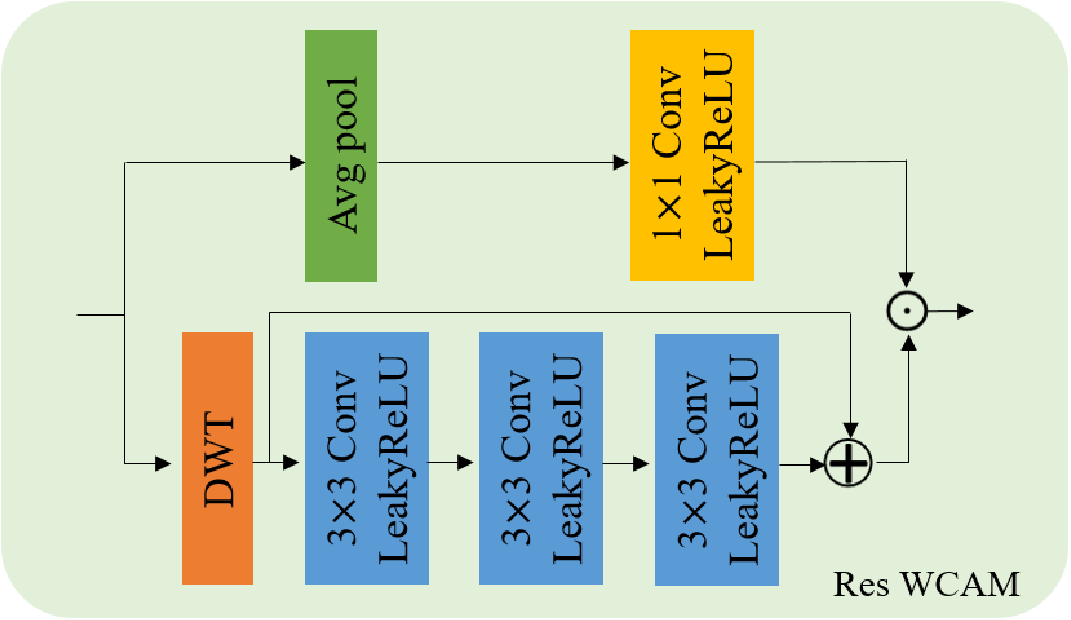
Вместо WCAM, в качестве последнего блока энкодера авторы используют Res WCAM. Это практически тоже самое, что и просто WCAM, но свёрточный слой с ядром 3 x 3, в первой ветке WCAM, заменён на ResNet блок.
Тренировка
Тренируются авторы на Outdoor-Rain наборе из статьи Ruoteng Li, et al. “Heavy rain image restoration: Integrating physics model and conditional adversarial learning”. Это набор из пары чистая фотография + таже фотография, с наложенным по специальному алгоритму дождём. Т.е. supervised обучение, но данные, некоторым образом, синтетические. В качестве штрафной функции используется SSIM для вейвлетов и L1.
Качество можно посмотреть на фотографии в начале. Авторы сравниваются с другими подходами по PSNR И SSIM и выигрывают (иначе не было бы смысла городить статью).