Быстрые нейронные сети на сжатых jpeg изображениях
Еще раз обращаясь к вопросу о нейронных сетях непосредственно на DCT коэффициентах из jpeg. Вчера разбирал статью про детектирование объектов на сжатых jpeg изображениях, хотя начать надо было по идеи не с неё, а с той, про которую сегодня. Т.е. всё таки задача классификации некоторым образом первична по отношению к детектированию, и статья, на которую посмотрим сегодня (от 2018 года) как раз про классификацию объектов сразу на DCT коэффициентах без декодирования до RGB картинки.
Авторы статьи в качестве сетки берут ResNet50 и заменяют RGB изображение $224 \times 224 \times 3$ на его представление в виде DCT коэффициентов: для $Y$ составляющей это будет $D_Y \sim 28 \times 28 \times 64$, а для $Cb$, $Cr$ составляющих, в четыре раза меньше $D_{C_b}, D_{C_r} \sim 14 \times 14 \times 64$. Тут всё логично, кроме разве того момента, что и здесь авторы не акцентируются на том, что плоскости для высоких частот будут практически сплошь состоять из нулей, но это не суть. Если исходить из размеров тензоров, то $D_Y$ можно отдавать на вход третьему блоку ResNet сети, а $D_{C_b}, D_{C_r}$ четвёртому.
Авторы, предлагают несколько вариантов того как объединять данные и подавать их в ResNet сеть, и приводят статистику качества и скорости классификации для каждого из вариантов. Плюс в качестве бонуса, они рассматривают как меняется качество и скорость работы сети на RGB данных, в случае, если начать прорежать слои ResNet из второго и третьего блоков (т.е. тех, которые “теряются” в DCT реализации) и что получится, если обучить “DCT преобразование” вместо того, которое стандартное в jpeg, т.е. насколько именно DCT влияет на качество классификации.
Итак какие есть варианты:
-
UpSampling - в этом случае $D_{C_b}, D_{C_r}$ масштабируются в 2 раза вверх по обеим осям, простым дублирование данных. После чего все три набора $D_Y, D_{C_b}, D_{C_r}$ объединяются получается тензор размера $D_{all} \sim28 \times 28 \times 192$, который после batch normalization подаётся на вход третьего блока ResNet сети. Причем, в первом свёрточном слое третьего блока, мы должны делать свёртку с stride 2, чтобы уменьшить пространственные размеры карты особенностей, но в данном случае свёртка делается с stride 1, и поэтому размеры выходного тензора после третьего свёрточного блока совпадают с классической ResNet.
-
UpSampling-RFA (Receptive Field Aware) - этот вариант повторяет предыдущий, только в данном случае e ResNet сохраняется и второй свёрточный блок, в который и подаётся $D_{all}$. Теперь stride 2 заменяется на stride 1 в свёртках и второго и третьего свёрточных блоков, чтобы вписаться в дальнейшую конфигурацию ResNet сети. Этот вариант отличается от предыдущего тем, что за счёт увеличения количества свёрточных слоёв, во-первых, увеличивается количество параметров сети, во-вторых, увеличивается размер квадрата исходного изображения с которого берутся данные для каждой особенности на выходе тех же свёрточных слоёв, что в варианте 1.
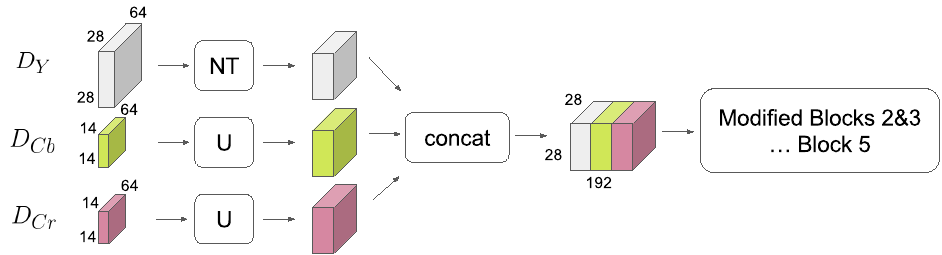
-
Deconvolution-RFA - тоже что предыдущий способ, только для масштабирования вверх используют десвёрточные (deconvolution) слои, веса которых обучаются в процессе тренировки сети.
-
Downsampling - вместо того, чтобы масштабировать тензоры с данными о цветности вверх, в данном случае, тензор $D_Y$ с данными о яркости масштабируется вниз. Потом примерно тоже самое, что и в случае UpSampling, только с учетом уменьшения размеров.
-
Late-Concat - здесь прогоняем $D_Y$ через свёрточный блок с уменьшением пространственных размеров вдвое, а $D_{C_b}, D_{C_r}$ через свёрточные слои. Потом объединяем и отправляем в остаток ResNet сети начиная с четвёртого свёрточного блока.
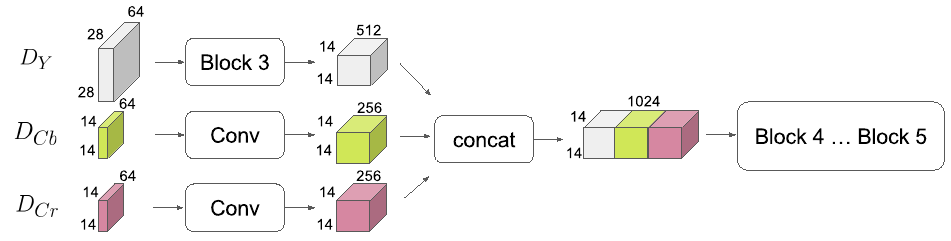
-
Late-Concat-RFA - смесь предыдущего и варианта 3. $D_Y$ - прогоняется через три свёрточных блока, настроенных таким образом, чтобы особенности на выходе собирали данные с прямоугольника на исходном изображении такого же размера, как если бы мы загоняли RGB картинку в классический ResNet. $D_{C_b}, D_{C_r}$ проходят через свёрточные слои как и в предыдущем варианте. После чего все карты особенностей объеденяются и передаются на вход четвёртому свёрточному блоку ResNet.
-
Late-Concat-RFA-Thinner - это попытка найти баланс скорость-качество, фактически тоже что и в предыдущем варианте, но уменьшается количество каналов в свёртках. Если посмотреть на результат - баланс вполне себе получается, качество падает, но всё-таки выше чем в Late-Concat, а скорость возрастает.
Результирующая табличка со статистикой:
Architecture | Top-1 err | Top-5 err | Top-1 | Top-5 | FPS
| | | Diff | Diff |
------------------------------------------------------------------------------
ResNet-50 RGB | 24.22 ± 0.08 | 7.35 ± 0.004 | | | 208
ResNet-50 YCbCr | 24.36 | 7.36 | +0.14 | +0.01 | 207
UpSampling | 25.07 ± 0.07 | 7.81 ± 0.12 | +0.85 | +0.45 | 396
UpSampling-RFA | 24.06 ± 0.09 | 7.14 ± 0.07 | -0.16 | -0.21 | 266
Deconvolution-RFA | 23.94 ± 0.015 | 6.98 ± 0.005 | -0.27 | -0.36 | 268
Downsampling | 27.00 | 8.98 | +2.78 | +2.36 | 451
Late-Concat | 24.93 | 7.62 | +0.71 | +0.27 | 401
Late-Concat-RFA | 24.08 | 7.09 | -0.14 | -0.25 | 267
Late-Concat-RFA-Thinner | 24.61 | 7.43 | +0.39 | +0.08 | 369
Выводы
Основной вывод, что авторам удалось одновремено повысить и скорость и качество используя DCT коэффициенты вместо RGB картинок. Смотрим на Deconvolution-RFA, UpSampling-RFA, Late-Concat-RFA. А еще можно повысить скорость практически вдвое, если несколько поступиться качеством - Late-Concat.